The best AI systems aren’t born from bigger models, but from better engineering.
最优秀的 AI 系统并非来自更大的模型,而是来自更好的工程设计。
[!CAUTION] 更新日志
2025.11.09 全文译自 Weaviate: The Context Engineering Guide
2025.11.12 修订“智能体”章节,增加内容:“从工程角度看智能体”、“如何让上下文“干净又高效”“
2025.11.16 修订“查询增强”章节,增加落地实践等内容
2025.11.17 修订“检索”、“记忆”、“提示词”等章节,每个主题增加如何落地实践等内容
引言
每一个使用大模型进行开发的程序员,最终都会面临同样的问题。最初,你手里有一个非常强大的模型,它能写作、总结、推理,展现出惊人的能力。然而,当你尝试把它应用到现实世界时,问题就开始浮现:它无法回答与你的私有文档相关的问题,对昨天发生的事情也一无所知。而当它不知道答案时,却常常一本正经地胡编乱造,仿佛自己非常确定。
问题不在于模型的智能,而在于它从根本上是“断开的”。它就像一个强大但孤立的大脑,无法访问你的特定数据、无法连接实时互联网,甚至无法记住你上一次的对话。这种孤立的根源来自它的核心架构限制:上下文窗口 。上下文窗口是模型的“工作记忆”,也就是它在执行当前任务时可以存放指令和信息的有限空间。每一个字母、数字、标点符号,都会占用这个窗口的空间。就像一块写满字的白板,一旦写满了,新内容就会覆盖旧内容。重要的信息可能会被“挤掉”,从而遗失。
光靠写更好的提示词是解决不了这个根本问题的。你得在模型的外围,搭建一个能支撑它运行的系统。
这就是上下文工程。
上下文工程 ( Context Engineering ) 是一门设计学科,它的目标是构建一种架构,让大模型在恰当的时机获得恰当的信息。它并不是要改变模型本身,而是要搭建桥梁,把模型与外部世界连接起来,让它能检索外部数据、连接实时工具,并拥有记忆,使它的回答基于事实,而不仅仅依赖训练数据。
接下来的内容就是这一系统的蓝图 ( blueprint ) 。我们将讲解那些能把一个“聪明但孤立”的模型转化为可靠、可投入实际生产的应用所需的核心组件。掌握这些组件的能力,是“一个普通demo”与“一个真正智能的系统”之间的分水岭。
让我们开始吧。
智能体
当你开始用大模型构建真正的系统时,很快就会碰到「静态流程」的局限。那种固定的“先检索,再生成”的配方,在一些简单的RAG ( Retrieval Augmented Generation,检索增强生成 ) 场景中还能凑合用,一旦任务需要判断、适应,或者多步推理,这种方式就完全不够了。
这时,“智能体” ( agents ) 就登场了。在“上下文工程” 的语境中,智能体负责管理系统中信息的流动方式和质量。它们不再是盲目地照着脚本执行,而是能够主动评估自己已知的信息,判断还缺什么,选择合适的工具,并且在出错时调整策略。
换句话说,智能体既是上下文的“建筑师”,也是上下文的“使用者”。然而,想要高效地管理上下文并不容易。如果缺乏良好的实践与系统支持,就很容易出错,而一旦上下文管理出现问题,整个智能体的能力都会受到严重影响。
什么是智能体?
但在讨论这个问题之前,先给智能体一个明确的定义。智能体是一种能够自主感知、决策和行动的 AI 系统,详细来说,一个智能体,一定是具备以下能力的:
- 根据信息流进行动态决策:不同于传统的固定流程程序,会根据环境和上下文动态决定下一步行为。
- 在多次交互中保持状态与记忆:智能体会“记得”自己之前做过什么,并利用这些历史信息来影响后续决策。
- 灵活地使用工具:智能体能灵活选择并组合工具,而不是依赖预先设定的固定流程。
- 根据反馈不断调整策略:当某种方法效果不佳时,智能体能够改变思路,尝试新的方案。
在系统架构上,智能体可分为两类:
- 单智能体架构 ( Single-Agent Architecture ) :这类系统尝试由一个智能体独立完成所有任务。对于中等复杂度的工作流程,这种方式通常表现良好,结构简单、控制集中。
- 多智能体架构 ( Multi-Agent Architecture ) :这类系统会将不同的任务分配给多个专门的智能体去完成。它能够支持更复杂的工作流程,但同时也会带来协调与沟通方面的挑战。
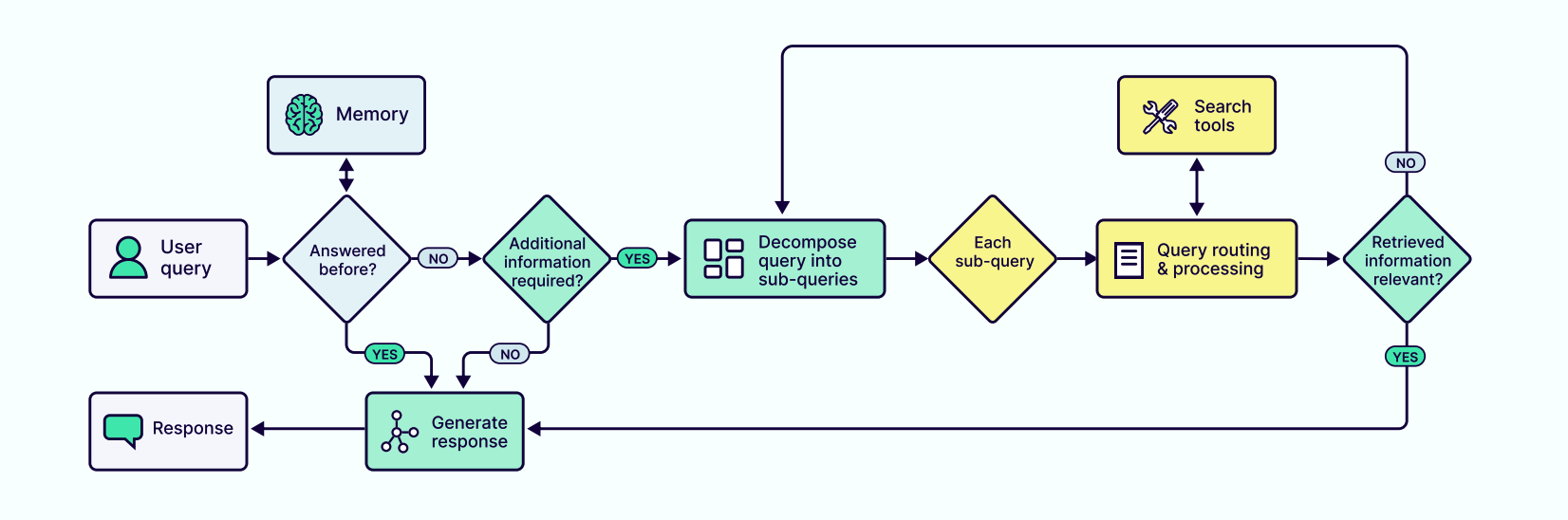
从工程角度看智能体
从工程落地角度看,一个智能体系统并不是一个抽象概念,而是一套循环运行的控制系统。它的基本运行逻辑是:
Perception → Reasoning → Action → Reflection ( Observation )
也就是说,智能体并非一次性完成任务,而是不断地“感知环境”、“推理下一步”、“采取行动”、“反思结果”。在每一个阶段,它都依赖上下文来判断自己的状态与外部条件。
在实际实现中,比如使用 LangChain Agent 或 ReAct 框架,这一循环通常表现为以下伪代码:
while true {
context = build_context(user_input, memory, retrieved_info)
thought = llm.generate("Thought:", context)
action = parse_action(thought)
result = execute_tool(action)
memory.update(action, result)
if task_done(result) {
break
}
}
这段逻辑反映了智能体如何与上下文工程结合:每次循环都动态构建上下文 ( 包括系统提示、任务状态、记忆与检索结果 ),再交由模型推理。上下文在这里不只是输入,而是系统状态的快照。
在 Claude Code 等系统中,智能体通过结构化数据 ( 如 JSON Task State ) 保存自己的状态。例如,Claude 的每次调用都包含 system prompt + task state + user input 三部分。这样,系统在任务恢复、错误重试时,可以无损地还原智能体思考现场。
上下文窗口的挑战
Context Hygiene 是管理智能体系统中最关键的部分之一。智能体不仅需要记忆和工具,还需要能够监控并管理自身上下文的质量。这意味着要避免信息过载,能够识别无关或冲突的信息,根据需要对信息进行裁剪或压缩,并保持上下文中的内容足够干净,以便进行有效推理。
[!TIP] Context Hygiene
hygiene 原意是“卫生”,这里是比喻用法,指“维持信息的健康状态”。这种比喻非常自然,常用于数据管理和安全领域,比如:
Code hygiene is essential for maintaining software quality. 良好的代码卫生对保持软件质量至关重要。
在写技术文章时,这个词能让抽象概念变得更形象,比如:data hygiene、security hygiene
由于大模型的上下文窗口容量有限,它在任意时刻只能容纳一定量的信息。这个基础性的限制直接决定了智能体及其系统目前能做到的事情范围。当一个智能体在处理信息时,它需要不断做出以下决策:
- 哪些信息应继续保留在上下文窗口中
- 哪些信息应暂时存储在外部,并在需要时再取回
- 哪些内容可以进行摘要或压缩,以节省空间
- 应为推理与规划预留多少上下文空间
人们常常会误以为,只要让上下文窗口更大就能解决这些问题,但事实并非如此。更长的上下文 ( 几十万甚至接近一百万个token ) 实际上会带来新的失败模式。
在模型达到最大 token 容量之前,其性能往往就开始下降。智能体可能会变得混乱,出现更多幻觉 ( hallucination ) ,或者根本无法维持原本的表现水平。这并不仅仅是技术层面的限制,更是所有 AI 应用设计中必须面对的核心挑战。当上下文窗口变大时,常见或更容易出现下面几类错误:
- 上下文污染 ( Context Poisoning ):错误或幻觉的信息混入上下文,被智能体不断重复使用,导致错误越积越多。
- 上下文分心 ( Context Distraction ):上下文内容太多,智能体被信息淹没,只会照搬旧思路,不再真正思考。
- 上下文混乱 ( Context Confusion ):无关内容挤满上下文,干扰判断,让智能体选错工具或听错指令。
- 上下文冲突 ( Context Clash ):上下文里出现矛盾信息,让智能体陷入两难,无法做出正确决定。
如何让上下文“干净又高效”
在真实系统中,Context Hygiene 不只是一个概念,而是一整套工程化的管理机制。为了让智能体始终在“正确的信息”上思考,工程师们通常会采用的策略有:上下文裁剪、上下文缓存、多层上下文结构、上下文验证。通过这些机制,智能体不再只是“塞满上下文”,而是学会了管理上下文,从“放多少进去”,到“放对的进去”。
当上下文内容越来越多,占用的 token 接近模型上限时,系统会主动“瘦身”。常见做法包括:
- 按时间:优先删除最早的记录
- 按重要性:让模型自己评估哪些对任务影响最大
- 按语义相似度:合并或去除重复内容
按时间裁剪是最直观、最简单的方式,就像整理自己的书桌,只保留最近在用的文件,把旧文件收起来或者扔掉。LangChain 就很擅长这一套,它提供了「记忆窗口」的概念。你可以告诉它,只保留最近五轮对话,把其余的内容丢掉。简单粗暴,但有效。
# 只保留最近 5 条对话
memory = ConversationBufferWindowMemory(k=5)
但问题是,如果最早的内容其实非常关键呢?比如一开始你告诉模型你的长期目标,时间裁剪可能就直接把它扔掉了。于是出现了更聪明的做法:不是简单扔掉,而是把旧内容压缩成“浓缩笔记”。想象你有一摞厚厚的会议记录,不可能每页都随手翻,但你可以让助理帮你提炼成一页精华。
LangChain 的 ConversationSummaryMemory 就实现了这个思路:滑动窗口 + 摘要压缩。它会按照消息条数或时间顺序保留一定数目的对话历史,比如“保留最近5条消息”,滑动窗口外面的旧消息会发送给大模型,浓缩成简短摘要,并在上下文中替换掉原始内容。
但这里存在一个问题是,如果最近的几条消息都很长,那么滑动窗口内的消息本身就可能超过最大 Token 限制,这时候,就需要动态的缩减窗口,比如:先保留最新消息,逐条“删除”最老的消息,直到在 Token 限制范围内。这里的“删除”打了引号,并不是真的直接把消息丢掉,而是将这些消息与原有的摘要一起发送给大模型生成新的摘要。
ConversationSummaryMemory 通过这种方式保证了两件事:一是模型上下文不会超限,二是历史信息的核心内容仍然被保留,就像桌面上的旧文件,即使被收起来,你也能通过精华笔记随时回顾。
LangChain 提供了不少这样非常基础的上下文管理工具,跟具体的内容可以参考其官方文档和源码。而像 Claude Code,则使用了更为复杂的上下文管理策略:分层记忆 + 重要性优先。它不仅会保留最新的信息,更强调哪些信息对当前任务最重要,并通过分层存储和累积摘要来保证模型在有限 Token 下仍能访问关键内容。
Claude Code 借鉴了认知科学中的记忆模型,构建了一个由短期记忆、中期记忆、长期记忆系统工作的三层架构。
短期记忆中存放与当前任务最相关的信息,比如:你正在修改的函数、光标附近的代码块、用户的最新指令等等。这一层的实现方式,就是一个简单的消息队列,可以迅速的访问到最新的消息,实时获取到当前对话的 Token 使用量 ( 大模型会在最新的消息中返回 Token用量 ),为后续的压缩决策提供依据。这一层消息更新频繁,一般不会被摘要,而是直接保留全文。
当对话或项目继续推进,Claude Code 会自动将就的上下文摘要化,形成“参考层”,这就是中期记忆。它保存次要但仍可能需要的信息,如项目结构、函数调用链、旧对话的摘要等,这些数据一般保存在数据库或缓存中。但短期记忆超限时,会将最老的短期记忆和旧的摘要一同压缩,就像我们前面提到的那样。中期记忆,就像定期整理抽屉,把一堆就文件打包层笔记,仅留下精华。
长期记忆是跨会话的知识存储层,Claude Code 有两种长期记忆机制。CLAUDE.md 文件是其显式长期记忆,这里面存储的是它对项目的全局理解 ( 比如:项目架构、主要模块、依赖关系等 )、用户工作偏好 ( 代码风格、命名习惯等 )、已完成任务的总结 ( 如何解决的某些 bug、为什么这么改 )、当前任务上下文的压缩摘要等。换句话说,CLAUDE.md 是一份 高层语义笔记,是 Claude 能“带脑子来上班”的关键。
除了 CLAUDE.md,Claude Code 背后还有一个语义向量数据库,里面存储了代码片段、重要的历史对话片段、Claude 自己生成的笔记和修改记录、重要的错误栈、调试日志、注释等等。当 Claude 需要理解某个问题时,会在这里按语义相似度检索出最相关的内容。这就像你脑子里装的模糊印象记忆,你可能不记得问题的答案,当记得曾经解决过类似的问题,就可以通过语义检索,快速召回旧的上下文。
关于长期记忆在工程实现上,我们可以借鉴 Claude Code 的实现机制,显式的长期记忆存文件,隐式的语义记忆存向量库。
前面提到的重要性,好像还没有体现。其实,虽然对话被压缩了,哪些在对话中被频繁读写的核心代码文件,其内容会被智能的重新加载回上下文,就像你即使清理了桌面,仍然会把几份最重要的文件留在手边。Claude Code 设计了一套评分算法来决定当前的任务要加载哪些文件,评分标准包括:访问时间、访问频率、被经常操作的类型、文件类型等。简答来说,一个项目的代码文件可能很多,但最核心的代码文件可能就那几个,而我们遇到的很多问题可能都需要大模型来阅读这些文件,所以才有了这样一个机制。
最后,如果你刚开始做上下文管理,先用 LangChain 提供的简单工具 ( 如 ConversationBufferMemory / SummaryBufferMemory ) 搭出原型,解决“上下文太长”的基础问题。等系统稳定后,再逐步引入分层记忆结构:让短期记忆管理当前任务 ( 如滑动窗口 ) 、中期记忆存摘要 ( 如压缩过的历史 ) ,长期记忆存入向量库,实现语义检索和持续学习。一句话总结:先把对话装进盒子,再学会分类存档,最后让智能体记得“它从哪儿来”。
查询增强
在上下文工程中,如何准备和呈现用户的查询 ( query ) 是最重要的步骤之一。如果不能准确理解用户到底在问什么,大模型就无法提供精确的回答。
虽然这听起来很简单,但实际上却相当复杂。这里主要有两个问题需要考虑:
第一,用户往往不会以理想的方式与产品交互。
许多产品,会假设用户的提问总是清晰、简洁、标点正确,而且包含了模型理解问题所需的全部信息。但现实中,用户的查询往往模糊、上下文不完整,或者直接就是一句自然语言,比如:“昨天那份报告里的第三项是啥?” 这类问题如果直接丢给产品,几乎不可能得到有效结果。因此,要构建一个真正可靠的系统,就必须实现能够应对各种输入的解决方案,而不仅仅是理想输入。
第二,流程的不同阶段需要以不同的方式处理查询。
一个 LLM 可以很好理解的问题,未必是最适合用来搜索向量数据库 ( vector database ) 的格式。反之,一个适合数据库检索的查询语句,可能又不足以让 LLM 准确的回答问题。因此,我们需要一种机制,使得查询能够根据不同的工具和流程阶段进行“增强” ( augmentation ) ,从而适配不同的需求。
请记住:查询增强 ( Query Augmentation ) 要解决的是整个系统开头的 垃圾进,垃圾出 ( Garbage In, Garbage Out ) 问题。如果最初的输入质量就不高,无论你使用多么复杂的检索算法、多么先进的重排模型、或多么巧妙的提示词设计,都无法完全弥补模型对用户意图理解错误的后果。
查询改写
查询改写指的是把用户原来的提问重新写成一个更有效、更容易被系统理解的问题。以前很多应用只是检索→阅读(retrieve-then-read),而现在更先进的做法是改写→检索→阅读(rewrite-retrieve-read)。这种方法可以把用户写得奇怪或不太规范的问题改写得更清晰、去掉多余或干扰理解的部分、加入一些常见关键词,让系统更容易找到正确的内容、甚至还可以把复杂的问题拆成几个更容易回答的小问题。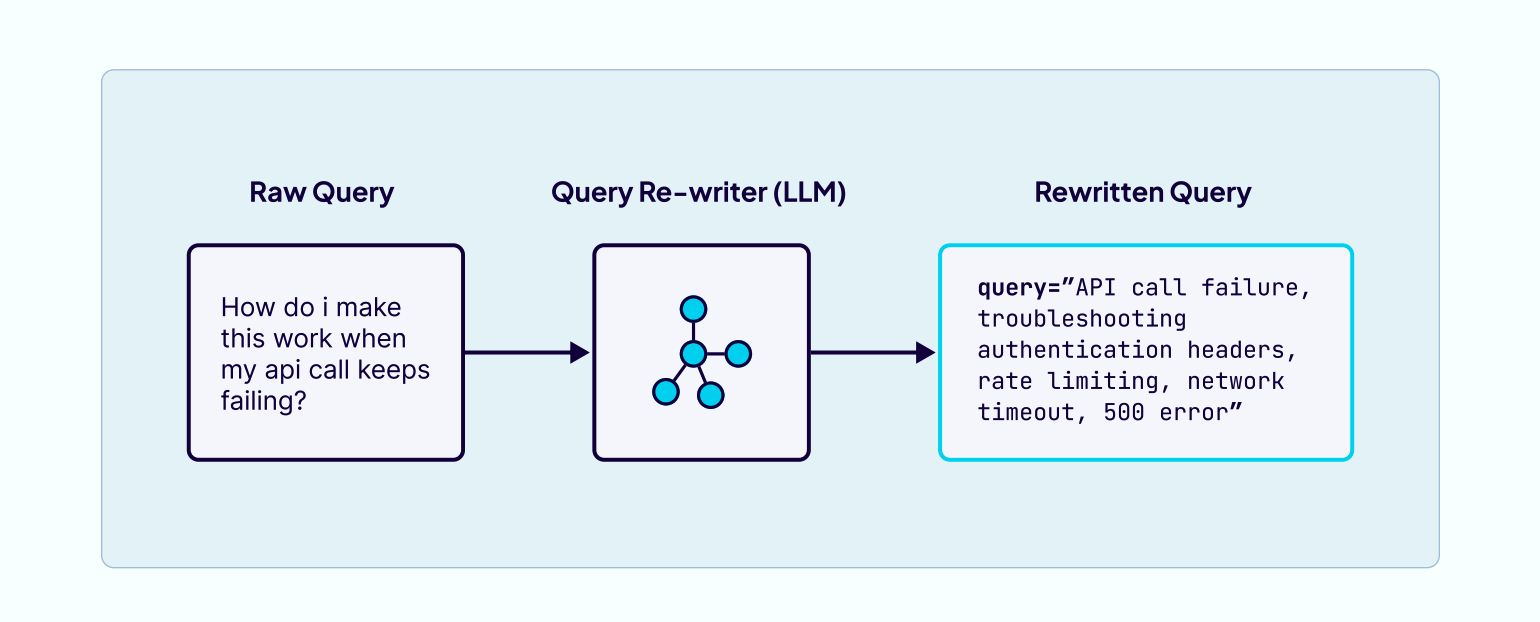
在 RAG ( 检索增强生成 ) 系统中,模型对句子的表达方式和关键词都非常敏感。也就是说,即使是意思差不多的句子,不同的表达方式可能导致结果完全不同。所以,“查询改写”就是通过下面几种方式来提升系统的理解力:
- 重写不清晰的问题:把模糊或结构混乱的提问,改成表达更准确、信息更集中的句子
原句:Tell me the one that’s not too expensive but works well.
改写:Which affordable laptop performs well for daily use? - 删除无关上下文:去掉那些和问题无关、反而可能干扰系统检索的信息。
原句:I was reading about iPhones last night, can you tell me how much the new Galaxy costs?
改写:What is the price of the new Samsung Galaxy phone? - 关键词增强:添加系统更容易识别的常用术语或关键词,提高匹配到正确资料的概率。
原句:How long does it last?
改写:What is the battery life of the iPhone 16 Pro?
查询改写的主流方法
最常见的策略是基于对话历史的改写,我们可以使用上文摘要作为提示,让模型在理解用户意图后重新表达问题。比如在 LangChain 中你可以这样:
rewritten_query = llm.generate(
f"Rewrite this question in full context:\n\n{chat_history}\n\nUser: {query}"
)
除此之外,也可以基于任务模版来改写。所谓的任务模板,就是把同一类任务抽象成固定的结构化查询格式。比如在企业中可能会有下面这样2种典型的任务:
- 查询文档 ( document_lookup )
Retrieve document where category='{category}' AND type='{type}' - 搜索知识库文章 ( search_knowledge )
search("knowledge_base", query="{query}", filters={tag:'{tag}'})
大模型接收到用户查询后,识别并输出用户意图,比如:“帮我找下合同模板”,大模型输出的意图分类可能是:
{
"intent": "document_lookup",
"category": "contract",
"type": "template"
}
此时系统就知道:
- 用户想“查找文档”
- 与合同相关
- 类型是模板
于是自动映射到对应的“结构化查询模板”,例如:
Retrieve document where category='contract' AND type='template'
基于任务模版的改写,跟大模型的工具调用、根据用户意图生成 SQL 等场景很类似,属于同一种系统能力:自然语言 -> 结构化动作计划,只是应用场景不同而已。如果再抽象一点,这与智能体框架中的 Planning -> Action 也是完全一致的。
查询改写双阶段架构
在许多生产级检索系统中,查询改写通常不会与检索混在一起执行,而是采用 “双阶段架构”:先改写,再检索。这种方式能显著提升系统的稳定性、可控性与可观察性。
第一阶段 Rewrite 的任务,是让系统先把用户的自然语言问题转化成一个更“适合检索”的版本。这里可能包括:规范化词语、补充缺失信息、添加隐式意图、将模糊提问转化为结构化查询等。这个阶段完全不接触底层索引,仅负责生成一个更明确、可执行、更贴近数据结构的“检索查询”。
第二阶段 Retrieve 则对改写结果执行正式检索操作,可能是向量搜索、BM25、混合搜索、SQL/DSL 查询等。这样做的好处是:检索层保持轻量与高性能,而理解层保持灵活可塑。
许多企业系统会采用 “Rewrite → Retrieve → Read” 的完整三段式流程:改写、检索、再由大模型生成可读答案。同时系统会将改写后的查询写入日志,使工程师可以基于真实数据优化改写策略、监控错误模式,从而让整体检索质量随时间不断提升。这种设计兼具工程可控性与模型智能,是现代检索增强系统的主流模式之一。
查询扩展
查询扩展是一种通过生成多个与用户输入相关的额外查询来提升检索效果的方法。简单说,就是系统不只使用用户原来的问题去搜索,而是自动想出一些意思相近或相关的问法,这样能让检索结果更全面、更准确。特别是当用户的提问模糊不清、信息不足时,或者系统采用关键词匹配的方式 ( 如搜索引擎、文档检索 ) 时,这种方法特别有用。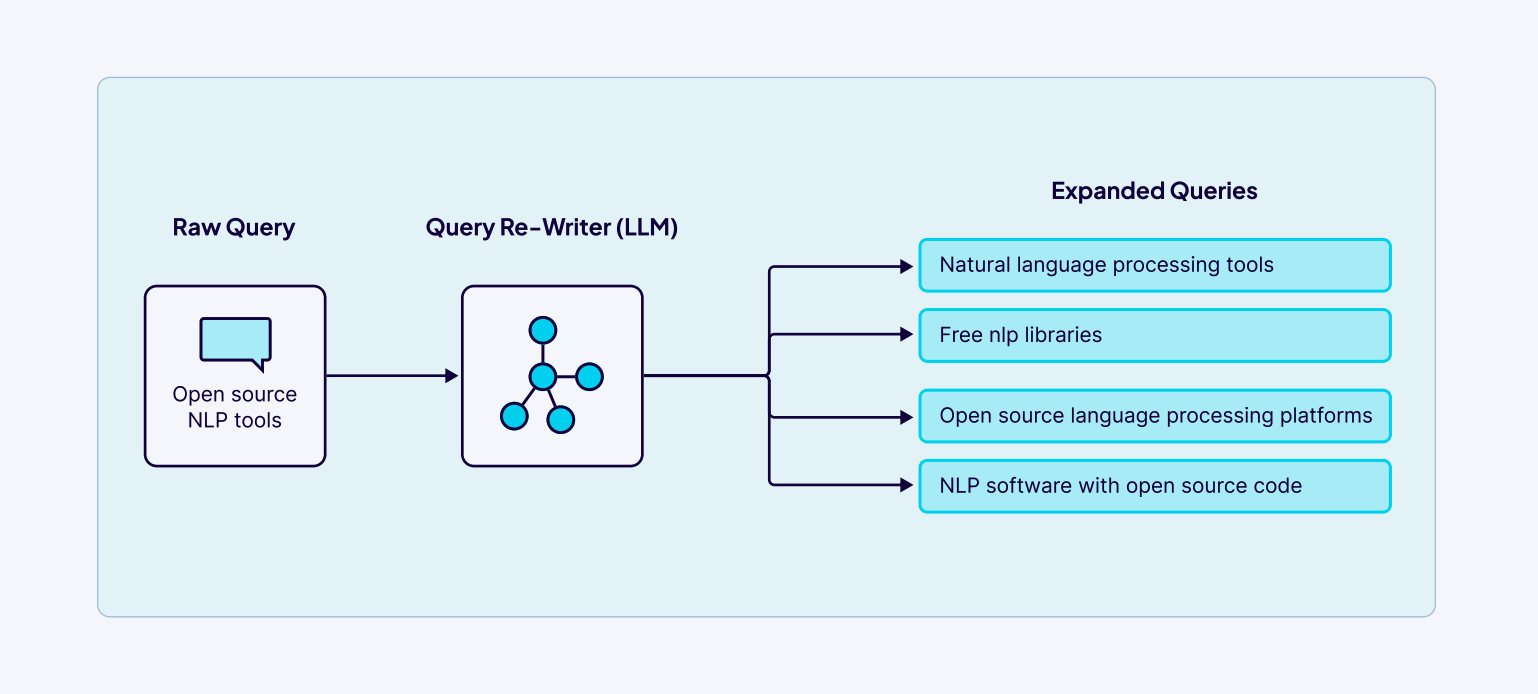
不过,查询扩展也不是完美的,它带来了一些需要谨慎处理的问题:
- 查询偏移:扩展后的查询可能会偏离用户最初的意图,从而导致检索到无关或跑题的结果。比如用户想问“apple laptop battery life”,系统却扩展出“apple fruit nutrition” ( 苹果水果营养 ) ,这就跑题了。
- 过度扩展:如果系统加了太多扩展词,虽然检索面更广,但准确度会下降,很可能搜出一大堆和主题关系不大的内容。
- 计算负担:每多生成一个扩展查询,系统就要多处理一次。这意味着响应速度变慢、计算资源消耗更多。
查询扩展在落地时,跟查询改写类似,都是通过大模型来生成,比如:
expanded_queries = llm.generate(
f"提出 3 个与此问题相关、但不偏离意图的检索查询:{user_query}"
)
然后将用户的原始查询与 LLM 扩展出的查询一起扔给检索系统 ( 向量数据库、全文检索数据库、搜索引擎等 )。由于查询扩展有上面提到的三个问题,在工程上,一般会增加一些约束,比如:
- 限制扩展的数量,比如:1 ~ 3 个
- 限制扩展变化幅度,比如:要求必须包含部分原始查询的关键字
- 过滤相差太远的扩展,比如:计算原始查询与扩展查询的 embedding 距离,距离太大就丢弃
- 对查询结果做 rerank,比如:使用原始查询和扩展查询检索出50条数据,再进行 Rerank 后得到最终的5条最相关结果
查询分解
查询分解是一种把复杂、多层面的提问拆分成几个更小、更集中的子问题的方法。每个子问题可以独立处理,这样系统能更准确地找到相关信息。这种技术特别适合那些需要从多个信息来源获取答案、或者涉及多个相关概念的问题。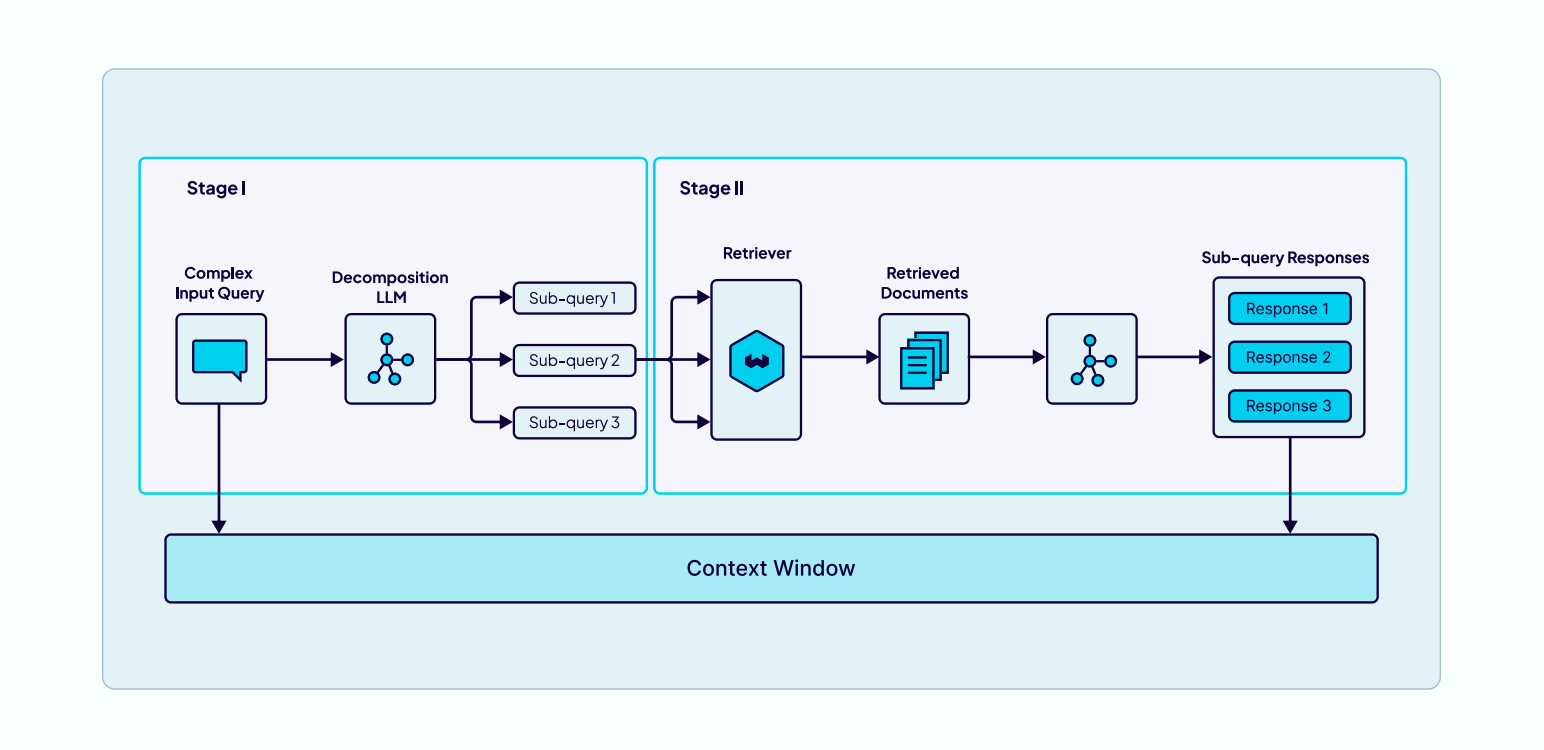
举个简单例子,用户问:“AI 在教育和医疗领域分别带来了哪些影响?”系统就可以拆成两个子问题:
- “AI 在教育领域的影响是什么?”
- “AI 在医疗领域的影响是什么?”
再分别检索、回答,最后整合成完整结果。
查询分解主要分为分解和处理两个阶段。在分解阶段,大模型会分析原始问题的结构,把复杂的问题拆成若干聚焦 ( focused ) 的小问题,每个小问题都针对原问题中的一个具体方面。在处理阶段,系统会分别处理每一个子问题,让每个子问题的查询独立地通过检索的 pipeline,这样可以更精准地匹配到相关文档或数据。
等所有子查询的结果都拿到后,上下文工程系统会将它们整合、总结、综合分析,最后生成一个完整、连贯的回答,从而解答原始的复杂问题。
在一些通用场景,通常使用大模型来拆解问题。但在一些垂直的场景,特别是包含许多内部知识的场景,通常使用 Graph-based 查询分解。Graph-based 查询分解可以把复杂问题理解为“图搜索问题”。如果说普通的文本检索像是在一堆文件里做全文搜索,那么图谱查询更像是在一张结构化的知识网络上做 BFS 或 DFS,实体是节点,关系是边,问题被转化成一次“沿图遍历”的任务。
当用户提出一个包含多个概念、多个关系的问题时,系统会先用 LLM 或 NER/NLP 技术把问题解析成图谱结构,比如识别出实体 ( 比如,前文的问题,可以识别出3个实体: AI、教育、医疗 ) 以及它们之间的潜在关系 ( 如:影响、应用于 ) 。随后,系统以这些节点为起点,在知识图谱里沿着可能的路径向外扩展,例如沿着“影响”“包含”或“属于”等边进行多跳遍历。这个过程有点像让算法“顺着知识的电路板走线”,自动拆分出更精确的子查询。
图搜索的优势在于,它不会局限于表面的文本匹配,而是能显式利用数据中的结构信息,因此特别适合多跳问答、关系推理、跨系统数据融合等场景。例如在企业环境中,一个问题可能同时涉及产品、部门、流程和日志四种数据源,图谱可以把这些异构结构统一在一张“知识地图”上,使查询分解更准确、更可控。虽然构建成本高,但在需要高置信度、可解释推理的系统中,它是最强的方案之一。
查询智能体
查询智能体是查询增强 ( Query Augmentation ) 中最先进的一种形式。它使用智能体 ( AI Agents ) 来自动管理整个查询处理流程,并将前面提到的几种技术 ( 如改写、扩展、分解等 ) 结合在一起,协同工作。
简单来说,查询智能体就像一个聪明的助手,它理解你的问题,知道数据库里有哪些信息,并能自动决定要怎么问、问什么、要不要重新问,直到找到最合适的答案。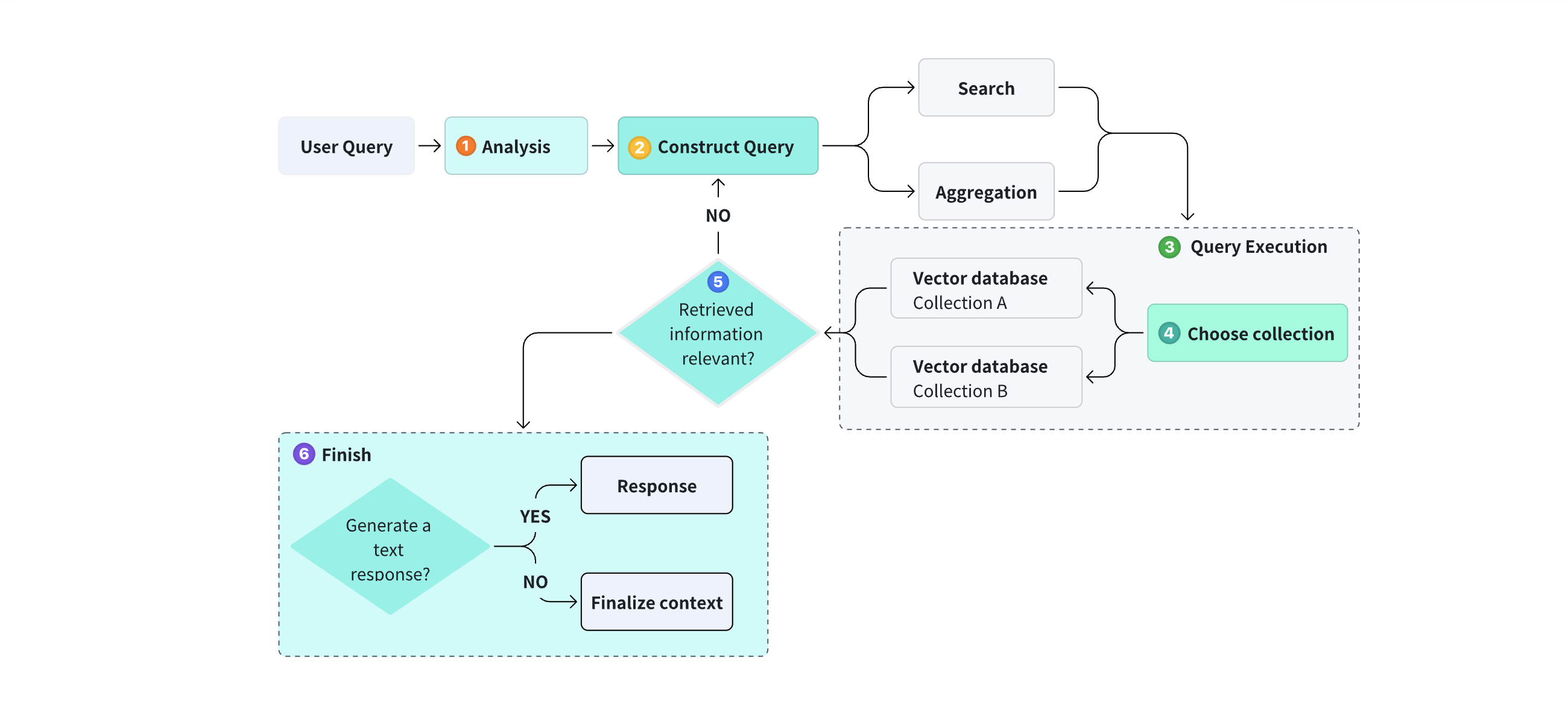
查询智能体的工作原理如图所示,用户用自然语言提出一个问题时,Query Agent 会做如下工作。
首先,任务分析模块 ( 图中1处 )对用户查询进行分析,判断用户问题属于:查资料?查数据库?还是必须分解?或是扩展?简单来说,在这个步骤,大模型不仅要分析用户的问题是什么,还要分析用什么查询方式才能得到答案。比如,在一些 Agent 中会根据用户输入得到类似于下面这样的 JSON 格式的描述:
{
"task_type": "multi_collection_search",
"requires_rewrite": true,
"requires_decomposition": false
}
接下来进入动态查询生成器 ( 图中2处 ),这个模块根据用户意图和数据库结构 ( data schema ) 动态生成查询,例如:
// 生成查询SQL
query = llm.generate(
f"根据 schema 生成 SQL:{schema}\n用户问题:{user_input}"
)
// 生成向量检索
retrieval_queries = llm.generate(
f"生成适合 embedding 检索的 2 个查询变体:{user_query}"
)
接着是查询执行 ( 图中3处 ),智能体会正式把构造好的查询发送给合适的数据集合,并根据任务需要选择执行一个或多个查询。智能体了解整个数据库结构,所以它能智能地决定要在哪些数据集合中搜索。比如,用户问题涉及“用户行为”,去 user_activity 表中搜索,这样在节省计算量的同时,让结果更准确,这就是多集合路由( 图中4处 )。
图中5处是一个结果评估器,智能体会根据原始问题来评估检索结果是否足够完整和相关。如果发现缺少信息,它会尝试不同的数据源,或重新构造一个新的查询再查一次,这种“自动补查”让智能体具备迭代式思考能力。评估的标准示例:
- 命中数太低,或者某些子问题根本没有命中内容
- LLM 判断当前的内容还不足以回答用户的问题
最后是最终结果生成器,智能体得到需要的所有数据后,使用生成式模型来整理和撰写最终回答,把数据结果转化为自然语言,清楚地呈现给用户。除此之外,智能体还会存储历史问题、上一轮查询的结果、用户任务意图、与当前任务相关的背景信息。这些信息将有助于智能体理解你的后续提问,就像人类一样,记得你刚才在说什么。
检索
大型语言模型的能力边界,本质上由它能访问的信息决定。尽管 LLM 在训练时接触过海量公开数据,但它对你的私有文档一无所知,也无法感知训练截止之后发生的新事件。如果你想让模型真正“用上你的知识”,就必须在正确的时机把正确的外部信息喂给它,这个过程就叫 Retrieval ( 检索 )。在主流 Agent 架构中,比如 Retrieval-Augmented Generation ( RAG ) ,检索是推理前的第一道关键工序。它的目标很明确:从庞大的知识库中,精准找出那一小段能直接回答问题的内容,并将其塞进 LLM 有限的上下文窗口里。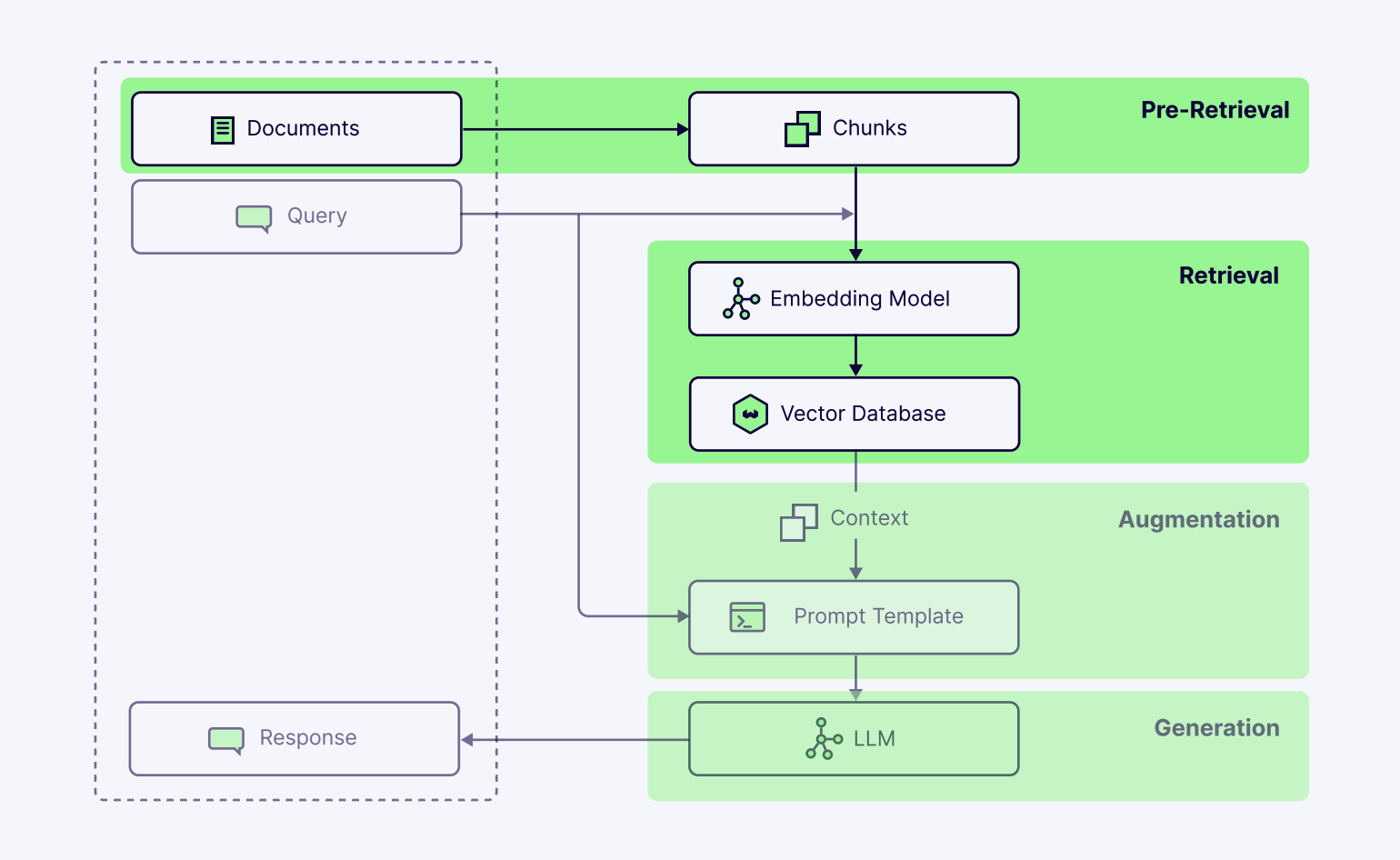
但现实远比概念复杂:一份企业知识库可能包含数万页 PDF、内部 Wiki、会议纪要或代码仓库,而主流 LLM 的上下文窗口通常只有几万个 token。你不能把整份 200 页的用户手册“硬塞”进去,而是要从中找到最个性、最相关的那一小段。
为了让庞大的知识库变得可搜索,并能迅速找到这“完美片段”,我们必须先把文档拆成一个个更小、更可管理的片段,这个过程叫 chunking ( 分块 ),它是整个检索系统的基石。chunking 往往比 embedding 更重要,因为向量检索的效果高度依赖 chunk 的语义纯度与上下文完整性。一个糟糕的 chunk 要么太碎 ( 缺乏上下文 ) ,要么太杂 ( 混合多个主题 ) ,都会导致 embedding 失真,最终让 LLM “看错材料、答非所问”。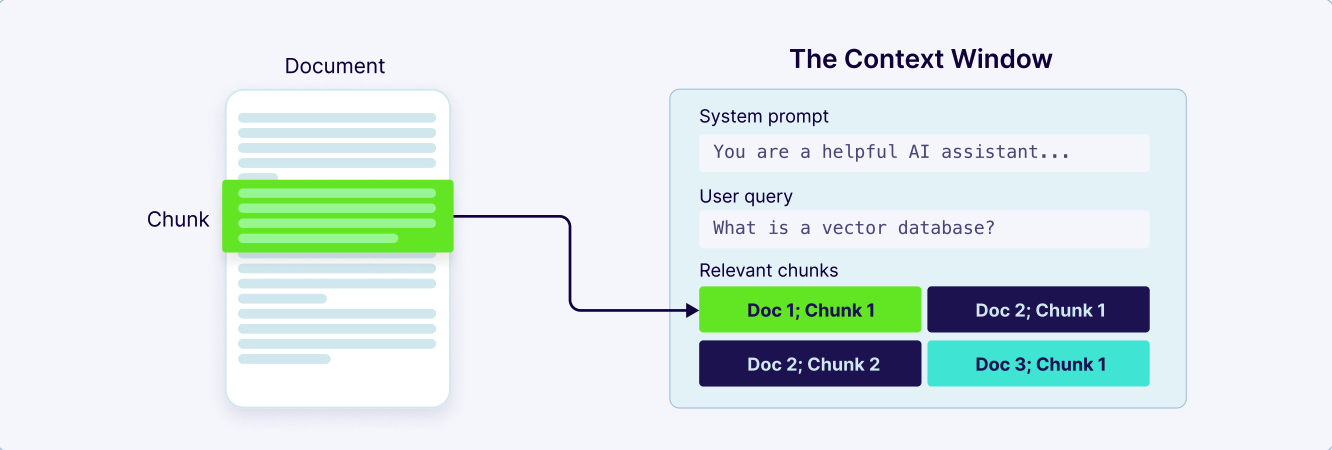
Chunking技术指南
Chunking ( 分块 ) 不是简单的文本切割,是你在设计检索系统时最重要的决策之一。如果分块做得好,你的系统就能像手术刀一样精准地定位到相关信息;但如果做得不好,即使是最先进的 LLM 也无法发挥作用。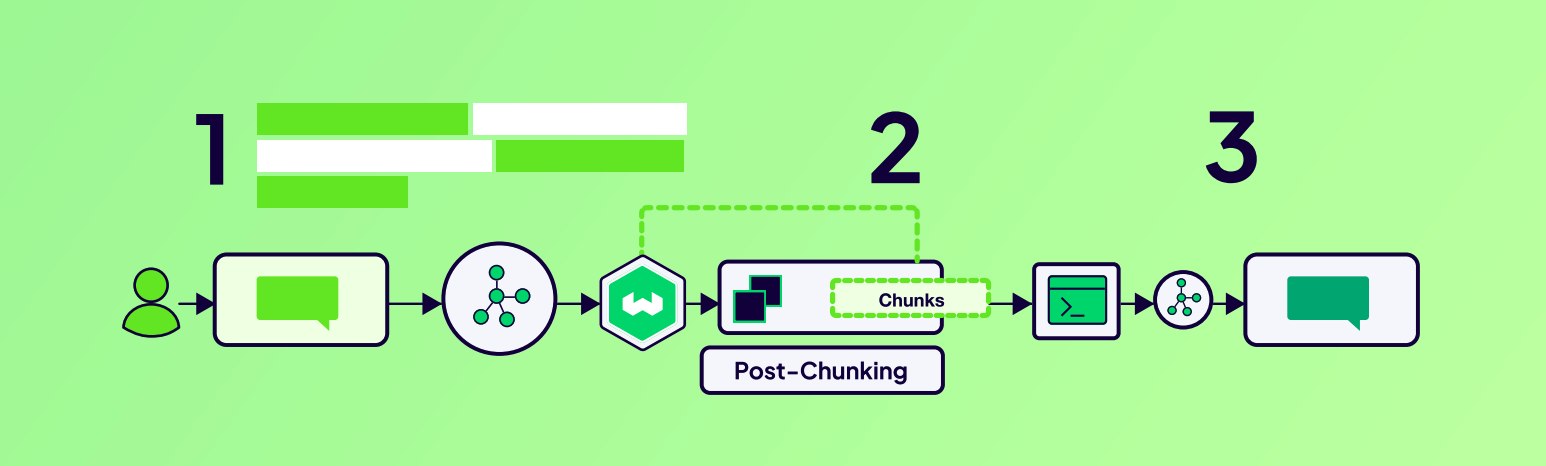
在设计分块策略时,你必须在两个相互竞争的优先级之间找到平衡:
- 检索精度:分块应当足够小,并且专注于单一主题。这样可以生成清晰而精准的嵌入 ( embedding ),使向量搜索系统更容易找到与用户查询最匹配的内容。如果块太大、混合了多个主题,那么生成的嵌入就会变得模糊且含噪,难以准确检索。
- 上下文丰富度:分块又必须足够大,能够自成一体并易于理解。当模型检索到一个分块后,它会把这段内容交给 LLM。如果分块只是孤立的一句话,没有任何上下文,即便是强大的模型也很难生成有意义的回答。
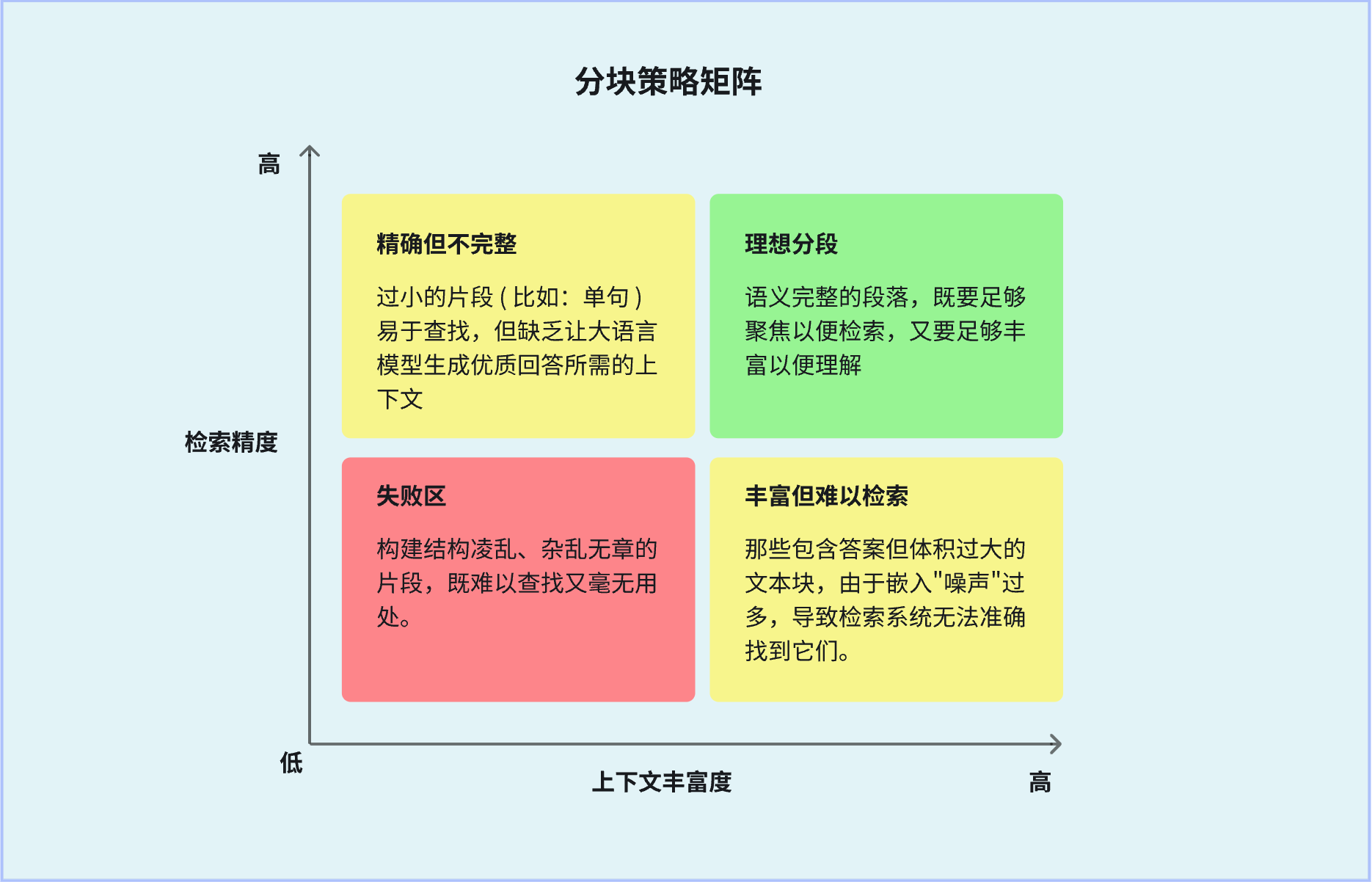
最终目标,是找到那个“分块甜点区 ( chunking sweet spot ) ”,让分块既小到足以精确检索,又大到足以提供完整的上下文。它没有统一标准,而是取决于你的数据类型与业务目标,比如:技术文档的 Chunk Size 推荐 256-512 个 Token,因为技术文档的条目一般比较独立,上下文较短;合同/报告这类文档推荐的 Chunk Size 为512-1024,这类文档术语密集,一个完整的条目往往都比较长。当然,更好的建议是用A/B测试验证。
基础分块方法
固定大小分块 ( Fixed-Size Chunking )
最简单的 chunking 方法,即固定大小分块,将文本按照固定的长度拆分 ( 例如每 512 个 token 为一块 )。这种方法快速、简单,但可能会把句子切断。常见做法是让相邻分块之间有一部分重叠 ( 例如 50 个 token ),以减少这种问题。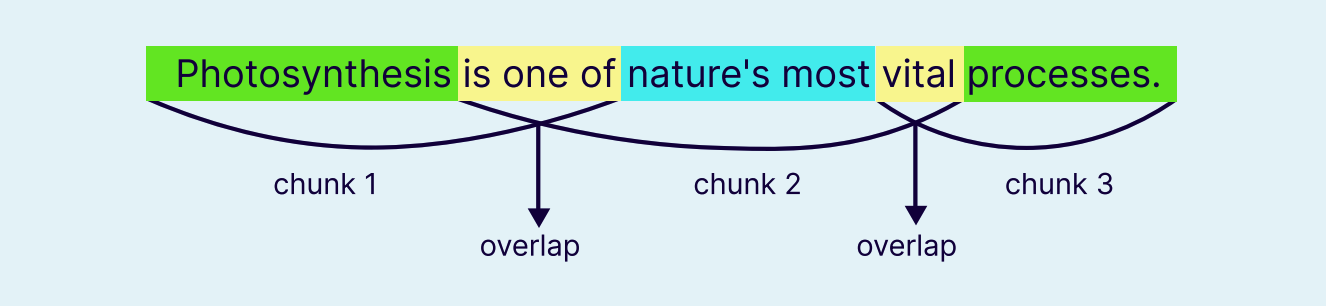
固定大小分块通常只出现在特定场景或早期原型中,它输出长度保持高度一致,完全不关心文本结构,在自然语言场景应尽量避免使用。在一些早期验证或测试场景中,可以使用 LangChain 提供的工具来实现无递归、无结构感知的纯固定切分:
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="", # 关键:空字符串 → 不按任何语义分隔
chunk_size=512,
chunk_overlap=50,
length_function=len # 按字符计数
)
递归分块 ( Recursive Chunking )
一种更智能的方式:递归分块,它会按照优先级列表的分隔符进行切分。比如:先按段落分,如果段落很长,再按句子,最后按单词。这种方式能尊重文档的自然结构,非常适合处理非结构化文本,因此被认为是一个稳妥的默认选择。
LangChain 中的 RecursiveCharacterTextSplitter 已内置递归分块逻辑,在实践时可直接使用:
# LangChain 示例:使用 tiktoken 兼容 OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
length_function=lambda x: len(tokenizer.encode(x)),
separators=["\n\n", "。", "!", "?", "\n", ",", "、", " "]
)
chunks = splitter.split_text(your_document)
基于文档结构的分块 ( Structure-Aware Chunking )
最后是,基于文档结构的分块。这种方法利用文档自身的结构,比如:Markdown 文件可以按照标题 (#、##) 进行切分;HTML 文件可以按标签 (<p>, <div>) 拆分;源代码可以按函数结构 ( AST 抽象语法树 ) 分块。
许多开源框架都提供了相应的工具来支持基于文档结构的分块,比如:
- LlamaIndex 的
MarkdownNodeParser/CodeSplitter - LangChain 的
MarkdownHeaderTextSplitter
为了提升检索效果,某些场景会采用更精细的策略。像 GitHub Copilot 在索引代码库时,会为每个函数生成独立 chunk,包含函数签名、docstring 和关键逻辑行,确保 LLM 能精准引用。因此,在实际落地中,应根据数据特性灵活设计分块方式,而非机械套用通用规则。
高级分块方法
语义分块 ( Semantic Chunking )
语义分块,这种方法不是按照符号切分,而是根据语义。它将意义相关的句子组合在一起,当话题发生变化时再创建新的分块。这样生成的分块语义连贯、上下文完整。
具体的实现步骤如下:
- 用 sentence-transformers ( 如 all-MiniLM-L6-v2 ) 为每句话生成 embedding
- 计算滑动窗口内句子对的余弦相似度
- 当相邻句 embedding 相似度低于阈值时进行切分
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = doc.split('。')
embeds = model.encode(sentences)
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
sim = cosine_similarity([embeds[i-1]], [embeds[i]])[0][0]
# 话题切换
if sim < 0.6:
chunks.append("。".join(current_chunk))
current_chunk = [sentences[i]]
else:
current_chunk.append(sentences[i])
语义分块适合那些主题转换频繁但无明显分隔符的文档,比如:学术论文、政策文件等等。它的计算开销比较大,建议离线预处理。
基于 LLM 的分块 ( LLM-Based Chunking )
基于 LLM 的分块,这种方法使用大型语言模型来智能处理文档,让模型根据语义生成一致的分块。它不依赖固定规则,而是让模型识别逻辑单元、命题,甚至可以对部分内容做总结,以生成保留原意的文本块。
基于 LLM 的分块的优势是能识别隐含逻辑(如“虽然…但是…”转折)、合并零散信息。劣势是效率比较低,成本较高。因此,在落地时建议仅用于高价值文档 ( 如合同、医疗记录 ),且尽量使用便宜的模型。这种分块方式在实现上就没啥好说的了,把内容给大模型,让它自己判断即可,比如:
请将以下文本划分为若干逻辑段落,每段应围绕一个完整主题,长度控制在 300–600 tokens。输出格式:[段落1]\n---\n[段落2]...
智能体分块 ( Agentic Chunking )
智能体分块,这种方法比基于 LLM 的分块更进一步,AI 智能体会动态分析文档的结构与内容,并自动选择最合适的分块策略,有时甚至会组合多种方法,为每份文档找到最优方案。
这种分块方式的真实落地场景极少,不仅仅是复杂,还有以下劣势:
- 延迟高:每个文档需额外 LLM 调用,吞吐下降 3–5 倍。
- 不可控:LLM 可能“过度总结”或“遗漏边界”,导致 chunk 丢失关键细节。
- 调试困难:分块逻辑变成黑盒,难以做 A/B 测试或归因分析。
如果企业内部已经有很好的 Agent 基建,且存在大量高度异构的知识 ( 代码、PDF文件、数据库、邮件、聊天信息等 ) 需要处理,那么可以尝试这种方式。
分层分块 ( Hierarchical Chunking )
分层分块,这种策略会在不同的层级上创建分块,例如:顶层是整体摘要,中层是章节级内容,底层是段落级细节。这种方式能让检索系统先从宏观了解,再逐步深入细节。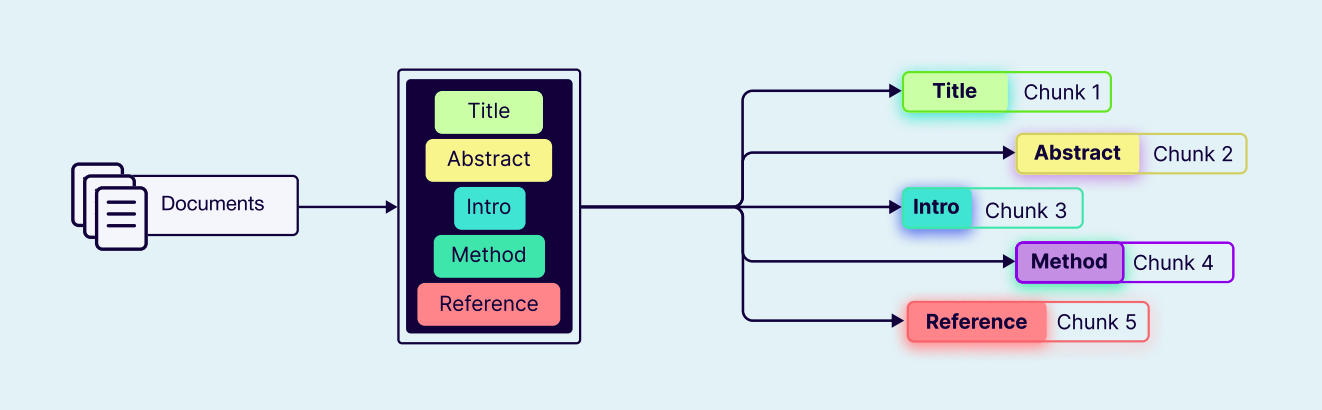
在检索时,先召回顶层节点,如果用户追问,再下钻到下一个层级。比如一个专利检索系统:
- 顶层:专利摘要
- 中间层:具体实现方式
- 底层:技术细节
当用户询问:“这项专利是什么?”,系统返回顶层 chunk;用户追问:“如何实现xxx?”,则下钻到中间层或底层。
分层分块的落地场景目前仍相对聚焦,主要出现在法律/专利检索、企业年报问答、长视频或播客转录文本处理等特定领域。这些场景有一个共性:用户的认知路径是“先看概要,再钻细节”。例如在播客转录中,用户通常先浏览节目大纲,发现感兴趣的话题后,才会深入查看对应的详细内容。
因此,只有当你的文档本身具备清晰的层级结构 ( 如章节-段落、主题-子议题 ) ,且用户行为确实呈现出“由粗到细”的查询模式时,才值得投入分层分块的设计与维护成本。否则,它带来的收益很可能无法抵消额外的存储开销和系统复杂度。
在实际落地中,可参考 LlamaIndex 官方示例:使用 HierarchicalNodeParser 将财报文档构建为三级 chunk 结构 ( 全文摘要 → 章节 → 段落 ),并结合其 AutoRetriever 实现支持多跳推理的分层检索。
后期分块 ( Late Chunking )
后期分块是一种反向的架构设计。它先对整份文档进行嵌入,以获取完整上下文的 token 级嵌入,然后再对文档进行分块。每个分块的嵌入都是基于这些上下文感知的预计算向量生成的。这种方法能最大程度保留全局语义。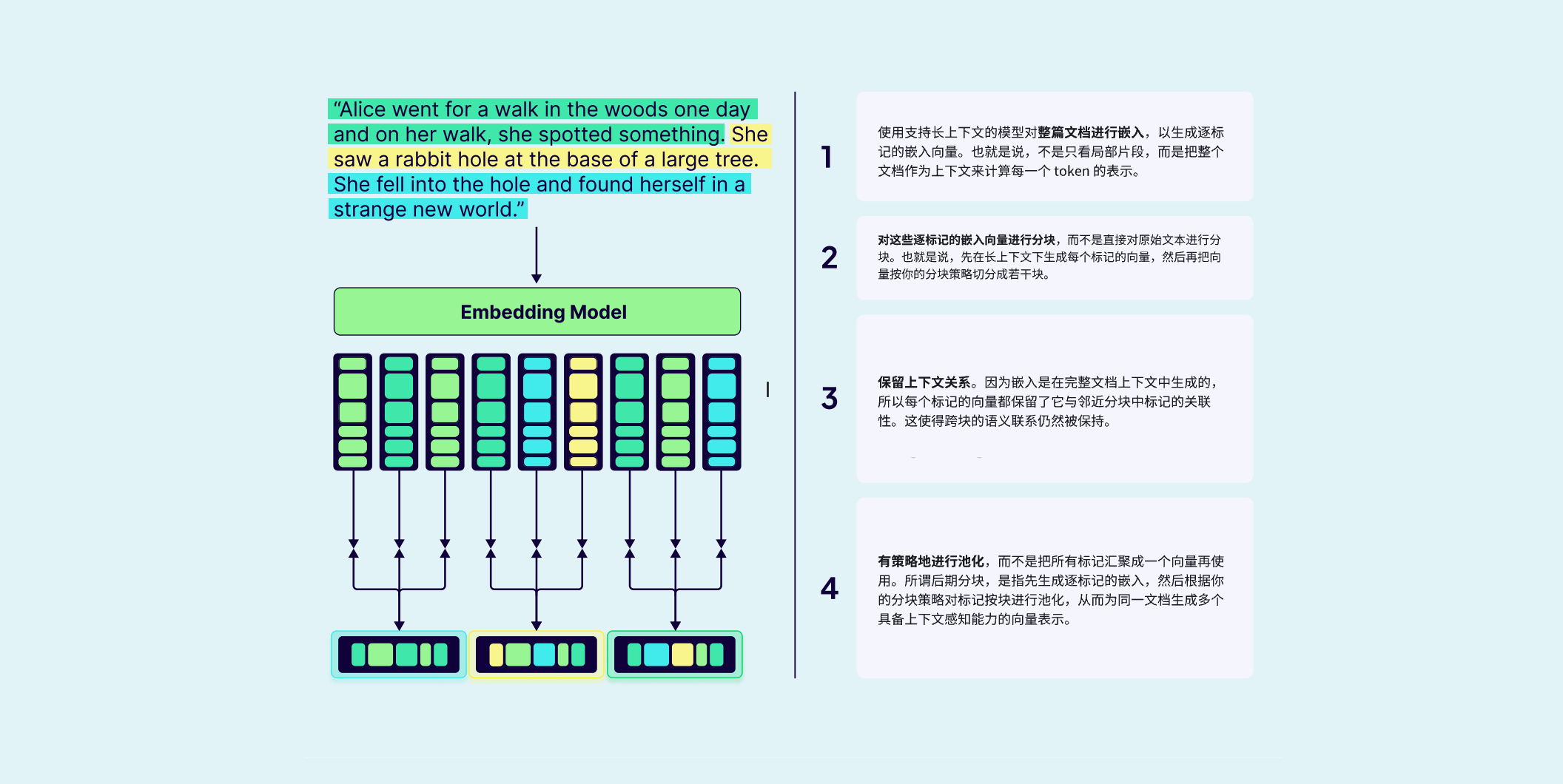
后期分块依赖于支持细粒度交互的专用模型 ( 如 ColBERT 或 SPLADE ) ,无法直接使用 OpenAI 的 embedding 接口,目前主要停留在学术研究和少数工业场景的早期探索阶段。鉴于其较高的技术门槛和有限的通用性,本文不再展开,感兴趣的同学可进一步查阅相关论文或开源项目。
预分块 vs. 后分块
除了如何分块之外,另一个关键的系统设计决策是何时分块,这个“时机”的不同,会导致两种主要的系统架构模式。
Pre-Chunking ( 预分块 )
这是最常见的方法,所有数据处理工作都在用户查询之前、离线完成。其工作流程是:清理数据 → 拆分文档 → 对每个分块进行嵌入并存储。其优点是,在查询阶段,检索速度非常快。因为所有工作都已经提前完成,系统只需要执行一次相似度搜索即可返回结果。缺点是,分块策略是固定的。如果你想更改分块大小或方法,就必须重新处理整个数据集,这可能非常耗时。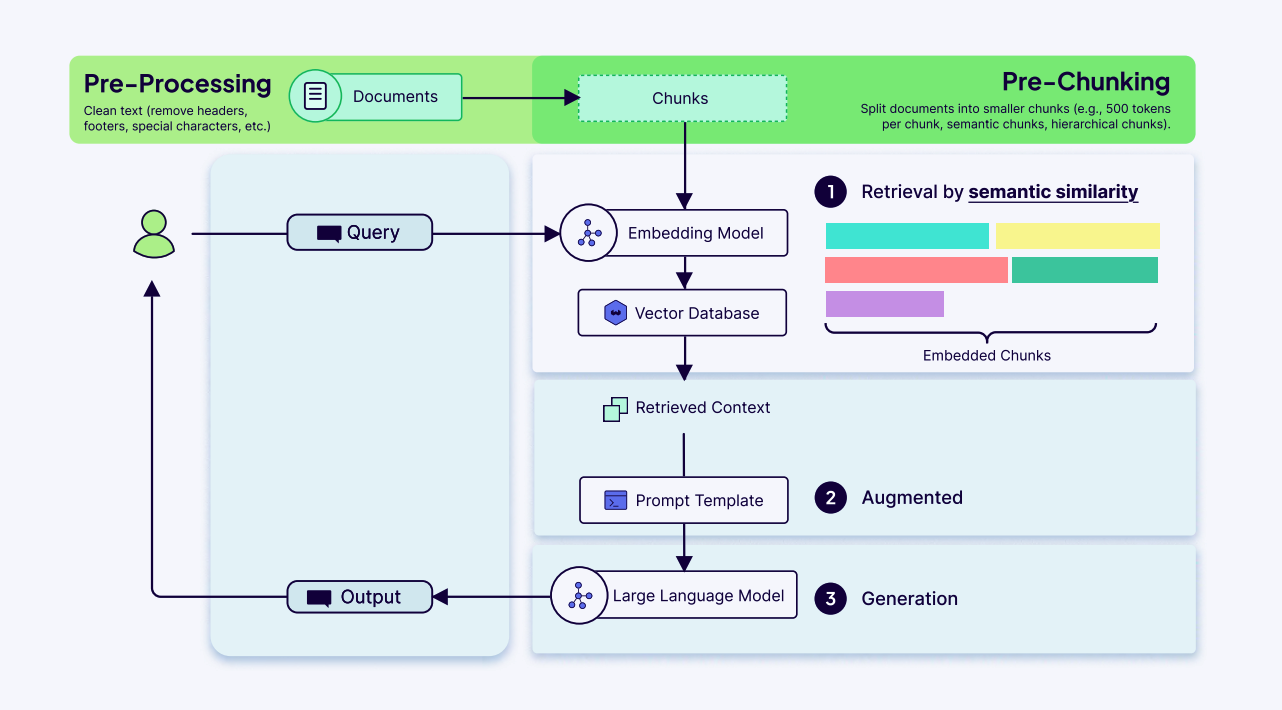
Post-Chunking ( 后分块 )
这是一种更高级、跟实时的替代方案,它在检索到文档之后、响应用户查询的过程中才执行分块。其工作流程是:存储原始文档 → 检索出与查询最相关的文档 → 动态进行分块。其优点是,灵活性极高,系统可以根据用户查询的具体语境,动态创建不同的分块策略,从而获得更加相关、上下文匹配度更高的结果。缺点是,会增加响应延迟,因为分块是在实时进行的,所以用户第一次收到结果的速度会变慢。此外,这种方法需要更复杂的系统架构来管理实时处理流程。
更具体的说,系统首先获取与查询最相关的完整文档,然后在内部对文档进行细粒度拆分 ( chunking ) 和重要性排序 ( reranking ),最后将处理后的片段放入大模型的上下文中,让模型能够理解、引用并生成高质量回答。与此同时,这些分块结果会被保存下来,用于下次快速检索或复用。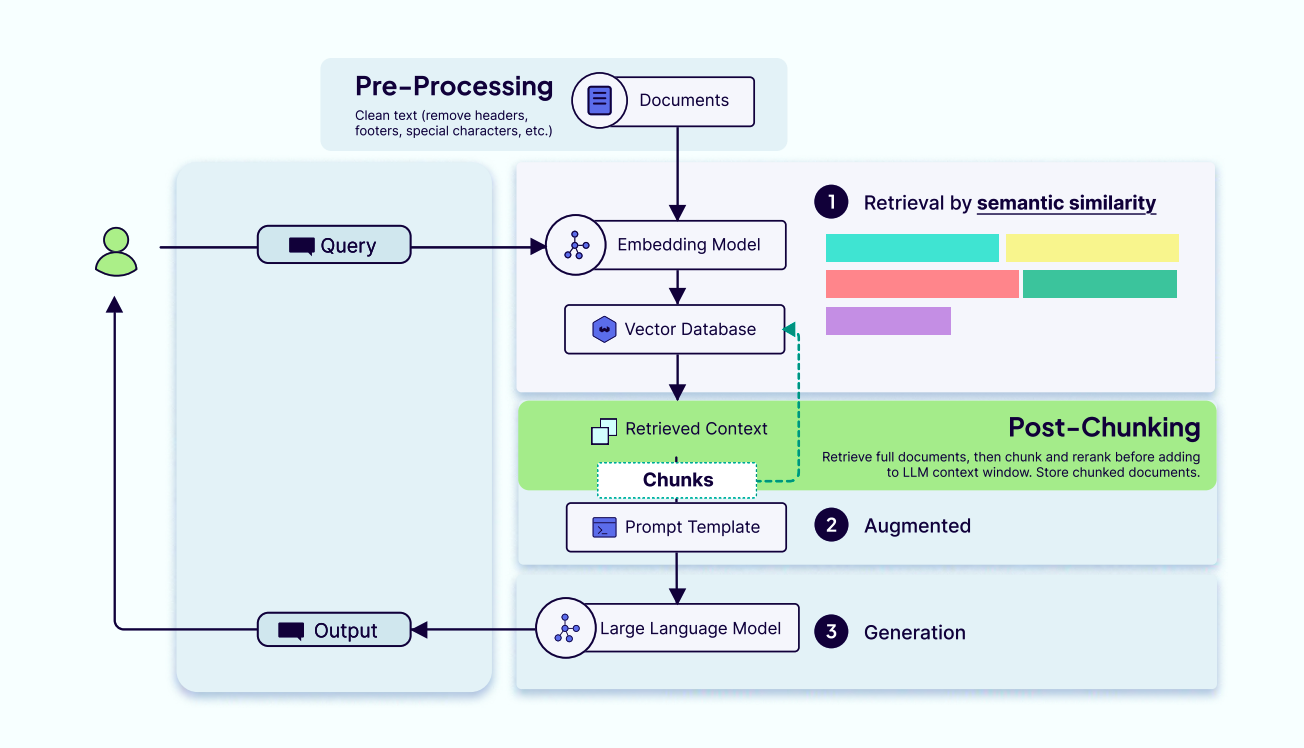
分块时机如何选择?
在现实中,Pre-Chunking 是当前 RAG 应用的主流选择,适用于绝大多数知识库问答、客服助手和文档检索场景。它通过离线处理将文档切分并嵌入向量库,查询时响应快、架构简单、易于缓存,非常适合数据相对静态、对延迟敏感的业务。而 Post-Chunking 则面向更高阶的需求:当用户问题高度动态、上下文依赖强,或原始文档结构复杂 ( 如长代码文件、法律条文 ) 时,系统可在检索到相关文档后再按需精细切分,从而提升语义匹配精度。尽管 Post-Chunking 延迟更高、实现更复杂,但在 Claude Code 等智能编程助手或专业领域问答系统中已初现价值。
两者并非替代关系,而是根据业务对“速度”与“精度”的权衡进行选型。
如何选择 chunking 策略
| 需求 | 推荐方案 | 工具链 |
|---|---|---|
| 快速上线 MVP | 固定大小 + overlap | LangChain + Chroma |
| 处理技术文档/Wiki | 递归分块 + Markdown 结构感知 | LlamaIndex MarkdownNodeParser |
| 代码问答 | AST 分块(按函数) | Tree-sitter + LlamaIndex CodeSplitter |
| 法律/医疗高精度 | 语义分块 或 LLM 分块 | sentence-transformers / Claude Haiku |
| 异构知识库 | 智能体路由 + 多策略 | AutoGen + 自定义分块器 |
| 长文档深度问答 | 分层分块 | LlamaIndex HierarchicalNodeParser |
| 极致检索精度 | 后期分块 + ColBERT | Vespa / ColbertV2 |
如果要给一点建议就是:先跑通递归分块 + reranking,90% 的场景靠它就能达到满意效果。只有当 baseline 准确率卡在瓶颈(如 <70%),且业务价值足够高时,才考虑引入后面的高级策略。需要着重强调的是,高级分块不是“银弹”,而是为特定场景定制的方案。在没有明确指征前,不必追求复杂。
提示技术
提示工程 ( Prompt Engineering ) 是通过精心设计输入指令 ( 即“提示” ) ,引导大型语言模型生成高质量、准确且符合预期输出的核心实践。LLM 的表现高度依赖提示的质量,措辞不清、结构混乱的提示,即便搭配完美的检索结果,也可能导致模型答非所问。
简言之,提示工程是你与 AI 高效协作的“接口设计”。在 RAG 系统中,它决定了模型如何理解检索到的上下文、如何推理、以及如何组织最终回答。本节将介绍几类关键提示技术,需要着重强调的是:它们的效果往往取决于是否与良好的上下文工程 ( 如精准 chunk、元数据注入、历史对话管理 ) 协同工作。
[!IMPORTANT] 重要提示
提示工程关注的是如何表达对 LLM 的指令,而上下文工程 ( Context engineering ) 关注的是如何组织信息,例如检索到的文档、用户历史、或特定领域知识,以帮助模型更好地理解和生成更相关的内容。下面介绍的技术 ( 如 CoT、Few-shot、ToT、ReAct ) 在与良好的上下文工程结合时,效果最显著。
经典提示技术
Chain of Thought 思维链
这种技术要求模型“逐步思考”,把复杂的推理过程拆解为中间步骤。在 RAG 中,当检索结果包含多个矛盾观点或技术细节时,CoT 能显著提升逻辑一致性。
实践时,可以在 LangChain 的 prompt template 中显式加入指令:
请按以下步骤思考:
1. 回顾检索到的相关信息;
2. 识别关键事实与潜在冲突;
3. 基于证据进行推理;
4. 给出最终结论。
少样本提示
这种方法会在模型的上下文窗口中提供几个示例,展示你想要的输出类型或“标准答案”。这些示例能帮助模型理解期望的格式、风格或推理方式,从而提升输出的准确性和相关性,在专业或技术领域中效果突出。
将 CoT 和 Few-shot 结合使用,可以同时引导模型的推理过程与输出格式,是一种高效的组合方式。
[!TIP] 提示1
让模型在 Chain of Thought 中的推理过程与具体场景紧密相关。
比如,可以要求模型:
- 评估环境
- 重复相关信息
- 解释这些信息对当前请求的重要性
[!TIP] 提示2
为了提升效率并减少 token 数量,可以要求模型以草稿式推理,每句不超过 5 个单词。
这样既能看出模型的思考过程,又能控制输出的长度。
高级提示策略
在经典技术的基础上,可以扩展出以下更高级的策略,能让 LLM 的行为更具层次:
Tree of Thoughts ( 思维树 )
ToT 是对 CoT 的扩展,它要求模型同时探索多条推理路径,像决策树一样生成不同的解法,并对这些方案进行评估与选择。这在 RAG 系统中尤为有用,特别是当模型面对多个检索文档、需要权衡不同证据时,ToT 能帮助它选择最合适的答案。
ReAct Prompting
ReAct 框架结合了 CoT 与智能体 ( Agent ) 的概念,让模型能动态地推理 ( Reason ) 与行动 ( Act )。模型会交替生成“推理过程”和“行动步骤”,以此与外部工具或数据源交互,并根据实时信息调整推理。这种方法能让模型在 RAG 管道中边思考边查证,利用外部知识不断更新判断,输出更准确、更具相关性的结果。
LangChain 的 ReActAgent 和 LlamaIndex 的 OpenAIAgent 均原生支持 ReAct,LlamaIndex 社区已有实验性 TreeOfThoughtAgent,在落地时可以参考。
工具使用提示
当你的 LLM 需要与外部工具交互时,清晰的提示对于确保正确选择和使用工具至关重要。LLM 有时可能会选择错误的工具,或错误地使用工具。为避免这种情况,提示应清楚地定义:
- 何时使用工具:明确说明在什么场景或条件下触发工具调用;
- 如何使用工具:提供预期输入、参数格式及期望输出;
- 示例:包含一些 Few-shot 示例,展示在不同场景中如何正确调用。
这种明确的指导 ( 应作为工具描述的一部分 ) 能帮助 LLM 准确理解各个工具的功能边界,从而减少错误、提升系统的稳定性与可靠性。
[!TIP] 提示:如何编写有效的工具描述
模型是否调用工具,完全取决于描述质量
编写工具描述时应注意:
- 用动词开头:例如 get_current_weather 优于 weather_data
- 明确输入参数:说明输入字段及其类型 ( 如 city: string、date: YYYY-MM-DD )
- 描述输出格式:告诉模型工具返回什么结果 ( 例如:返回包含 “high”、“low” 和 “conditions” 的 JSON )
- 说明限制条件:例如“仅适用于美国城市”或“仅支持近 7 天数据”
使用提示框架
如果你的项目涉及大量提示设计,或希望系统地优化 LLM 表现,可以考虑使用一些专门的框架,例如:
- DSPy
- Llama Prompt Ops
- Synalinks
不过,使用这些框架不是必须的。只要遵循前面提到的原则 ( 清晰指令、Chain of Thought、Few-shot Learning、以及高级策略 ),就能实现非常高效的提示效果。可以把这些框架看作是复杂项目的辅助工具,但不是日常提示工程的必需品。
记忆
当你在构建智能体时,记忆并不是一个额外的功能,而是赋予它生命的核心。没有记忆,一个 LLM 只是一个强大的、但无状态的文本处理器。它一次只处理一个请求,没有任何历史感。而有了记忆,模型才能变得更像一个“有意识”的存在:能保持上下文、从过去学习、并在运行中不断调整。
Andrej Karpathy 曾做过一个非常形象的比喻:LLM 的上下文窗口就像计算机的 RAM,而模型本身就像 CPU。
- RAM 里装的是“此刻正在思考的东西”;
- CPU 负责处理这些信息并输出结果。
但问题来了:RAM 是有限的。就像你同时开了几十个浏览器标签页,电脑会变卡一样,LLM 的上下文窗口也会被迅速填满,每一条用户消息、每一次工具调用、每一个中间结果,都在消耗宝贵的 token 配额。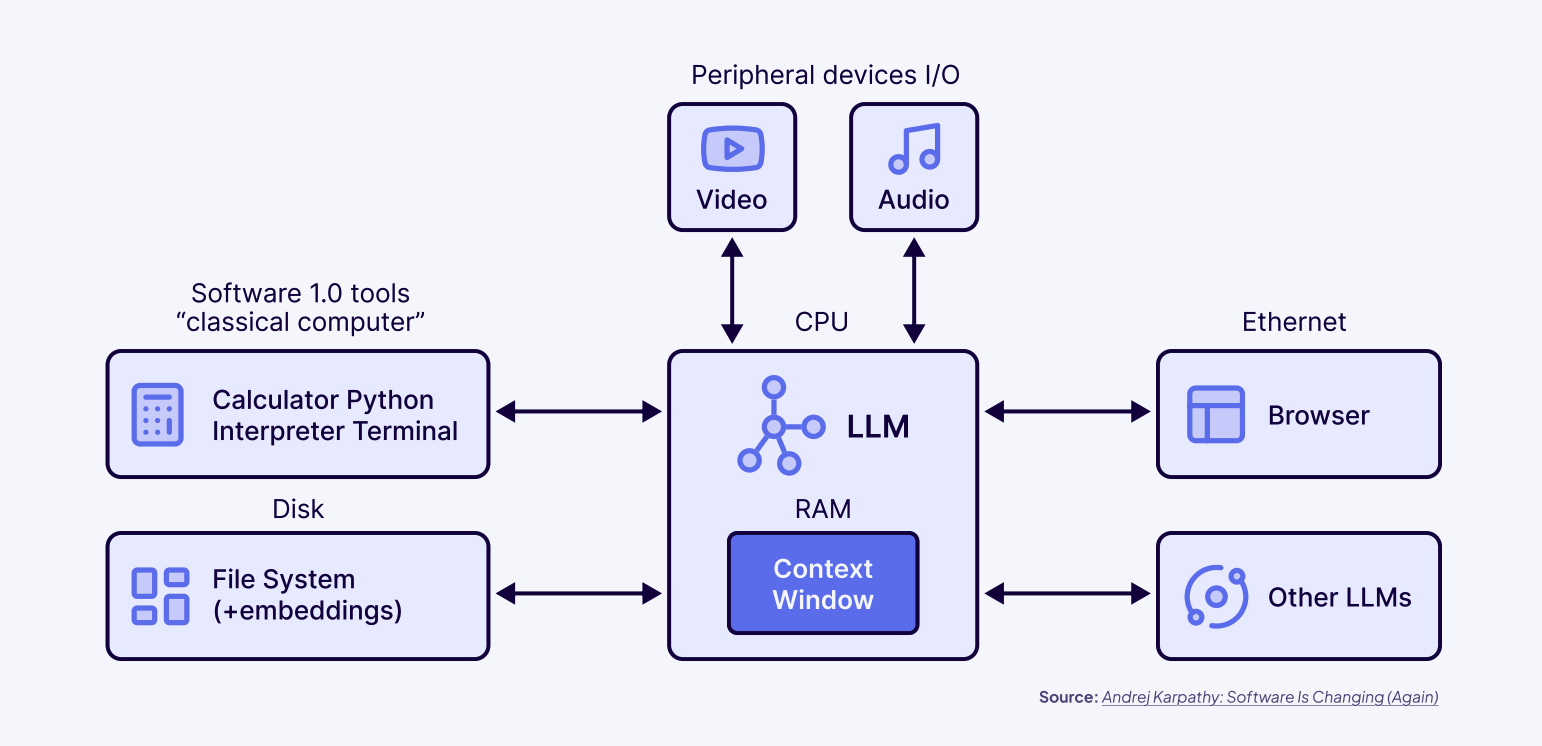
于是,“上下文工程”成了一门关键技艺。它的目标不是往提示词里塞得越多越好,而是聪明地调度信息流:把最关键的内容留在“工作区”,把暂时不用的信息优雅地“卸载”到外部存储中。
上下文卸载 ( Context Offloading ) 指的是将非即时需要的信息存储在 LLM 的上下文窗口之外 ( 例如外部工具或向量数据库中 ) ,只在必要时召回。这样可以释放有限的 token 空间,让上下文中只保留“最相关”的信息。
智能体记忆的结构
为了让智能体既灵活又可靠,我们通常采用分层记忆结构,就像人类大脑也有短期记忆、长期记忆和程序性记忆一样。
短期记忆 ( Short-Term Memory )
短期记忆是智能体的“即时工作区”,即“此刻”的内容。它被装入上下文窗口,用于实时推理与决策。这种记忆依赖上下文学习 ( in-context learning ),通过在提示中直接包含最近的对话、行为或数据实现。但由于模型的 token 数有限,挑战在于效率。关键在于保持内容精简,既不遗漏后续任务所需的重要信息,又能减少成本与延迟。
长期记忆 ( Long-Term Memory )
当任务超出单次对话范围,或需要调用历史经验时,就得靠长期记忆了。它把信息存在外部系统 ( 如向量数据库、图数据库或文档仓库 ) ,需要时再检索回来。这类记忆通常由 RAG 技术驱动:用户提问 → 智能体查询知识库 → 召回相关片段 → 注入上下文 → 生成答案。
长期记忆可以包含多种类型,比如:情节记忆 ( Episodic Memory ) 用于存储特定事件或交互;语义记忆 ( Semantic Memory ) 用于存储通用知识与事实,还可以包括公司文档、产品手册、或专业领域知识库。这样,智能体就能用事实支撑回答,保持知识的准确性。
混合记忆结构 ( Hybrid Memory Setup )
真实世界中的智能体几乎都采用混合记忆架构:短期记忆保速度,长期记忆保深度,再加上一些专用缓冲区,形成精细控制。比如:
- 工作记忆 ( Working Memory ):临时存放某个多步骤任务相关信息的区域。例如,订机票时,它会暂存目的地、日期、预算等数据,任务完成后再清空,而不会污染长期记忆。
- 程序性记忆 ( Procedural Memory ):帮助智能体学习和掌握流程。通过观察成功的工作流,智能体能逐渐“内化”任务步骤,让执行更快、更稳定。
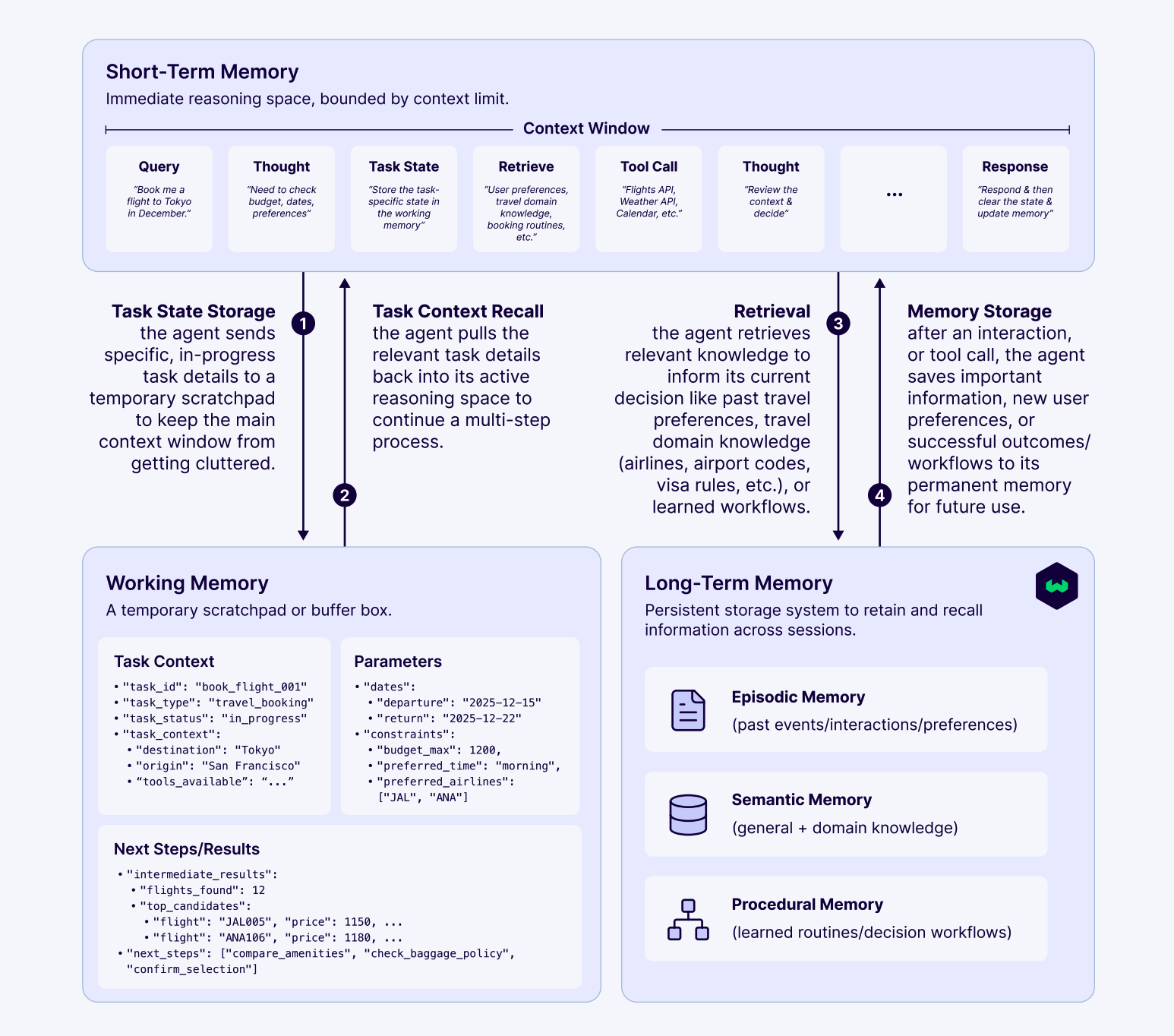
理解这张图,关键在于理解哪些信息,以什么样的结构,在什么阶段被送进大模型的 Context Window。从图中可以看到,Thought、Tool Call、Response 是与大模型交互过程中实时响应的数据,除此之外,通常有三类数据会被送到大模型的 Context 中:
- User Query:用户发起的自然语言请求,总是需要传入的
- Task State:当前任务的结构化状态( 任务描述、参数、进度等 ),这类数据一般是结构化的 JSON 数据,所以最好经过压缩或转换后传入
- Retrieved Knowledge:检索到的知识、偏好、规则等,通常以摘要或选定条目的形式传入
其中,Task State 从工作记忆中读取,Retrieved Knowledge 从长期记忆中读取。具体的流程大致是,但用户发起任务时,Agent 创建一个 Task State 结构在内存中。每次调用工具、做出决策后,更新 Task State 中对应的字段。但任务暂停或切换时,将 Task State 写入 Working Memory 中,重新激活任务时,从 Working Memory 中读取回来。任务完成后,从中提取部分内容写入 Long-Term Memory。
以图中的示例为例,其 Working Memory 中的内容为
{
"task_id": "book_flight_001",
"task_type": "travel_booking",
"task_status": "in_progress",
"parameters": {
"dates": {"departure": "2025-12-15", "return": "2025-12-22"},
"constraints": {"budget_max": 1200, "preferred_time": "morning"}
},
"intermediate_results": {
"flights_found": 12,
"top_candidates": [
{"flight": "JAL005", "price": 1150},
{"flight": "ANA106", "price": 1180}
]
},
"next_steps": ["compare_amenities", "confirm_selection"]
}
如果大模型的输入 Token 限制比较大的话,可以直接把 JSON 传给大模型;如果限制较小,可以将其简化为自然语言化的摘要,比如:
You are in the middle of a travel booking task (task_id: book_flight_001).
So far, the user wants to fly from San Francisco to Tokyo between Dec 15–22, 2025,
prefers morning flights, and has a budget under $1200.
You’ve found 12 possible flights, with top candidates being JAL005 ($1150) and ANA106 ($1180).
Next steps: compare amenities, confirm selection.
这些内容通常会拼接到上下文输入的前面,例如:
SYSTEM PROMPT:
You are an autonomous travel booking agent. Use the information below to make decisions.
[Retrieved Knowledge]
...
[Current Task State]
...
[User Query]
Book me a flight to Tokyo in December.
构建高质量记忆系统的四大原则
记忆管理做得好,智能体就聪明;做得差,反而会“越学越错”。以下是一些构建高质量记忆系统的原则:
定期清理与优化记忆
记忆不是“一次写入、永久保存”的系统。它需要定期维护:清理重复项、合并相关信息、删除过时数据。衡量标准是“最近性”和“使用频率”。如果一条记忆既旧又几乎不被访问,它就可能是删除候选。尤其在快速变化的环境中,旧信息甚至可能变成负担。例如,一个客服智能体可以自动清理超过 90 天的已关闭对话,仅保留摘要 ( 用于趋势分析 ),而非完整对话内容。
精选要保存的内容
不是每次交互都值得存入长期记忆。系统应当在保存前对信息的质量与相关性进行筛选。如果不加甄别地保存错误信息,会导致上下文污染,智能体反复犯相同的错误。防止这种情况的一个方法是:让 LLM 自我反思,并给交互结果打一个“重要性分数”,再决定是否存入记忆。
针对任务定制架构
没有万能的记忆方案。客服机器人需要强大的情节记忆来回忆用户历史;而财报分析智能体更需要强大的语义记忆来存储行业知识。最好的方式是从最简单的方案开始 ( 例如最近 N 次对话缓冲区 ),然后随着需求增长逐步加入更复杂的机制。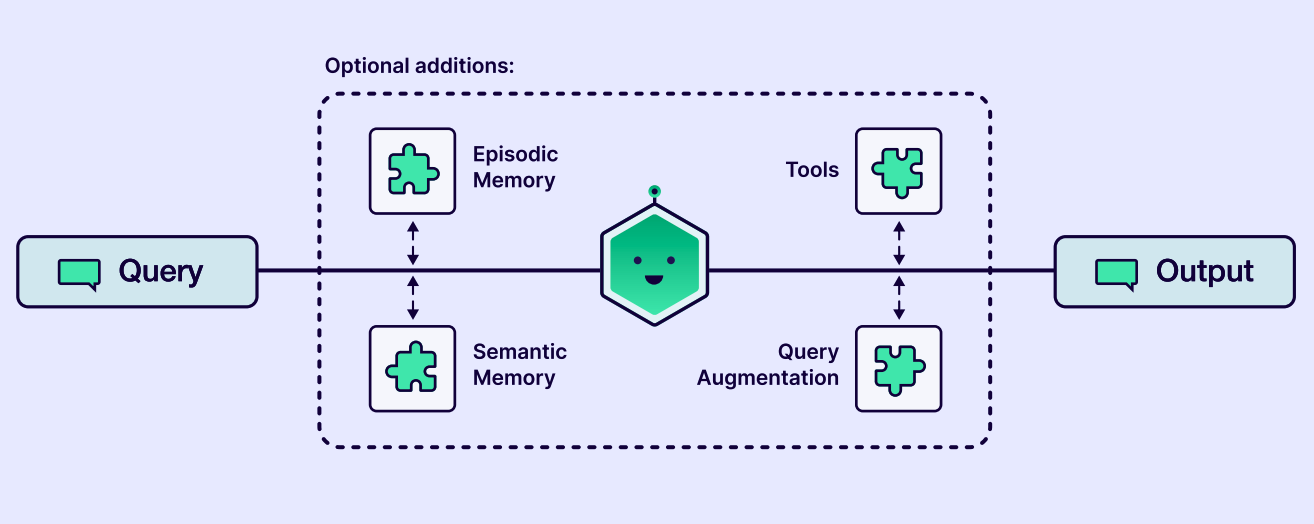
精通检索艺术
一个好的记忆系统,关键不在于能存多少,而在于能否在正确的时机取出正确的信息。简单关键词匹配往往不够,可以引入更智能的检索策略:
- 重排序:用 LLM 重新排列检索结果,提高相关性;
- 迭代检索:多轮改进搜索查询,逐步锁定最相关的信息。
像 LangChain 的 MultiQueryRetriever 或 LlamaIndex 的 RouterQueryEngine,都内置了这类能力,能显著提升召回质量。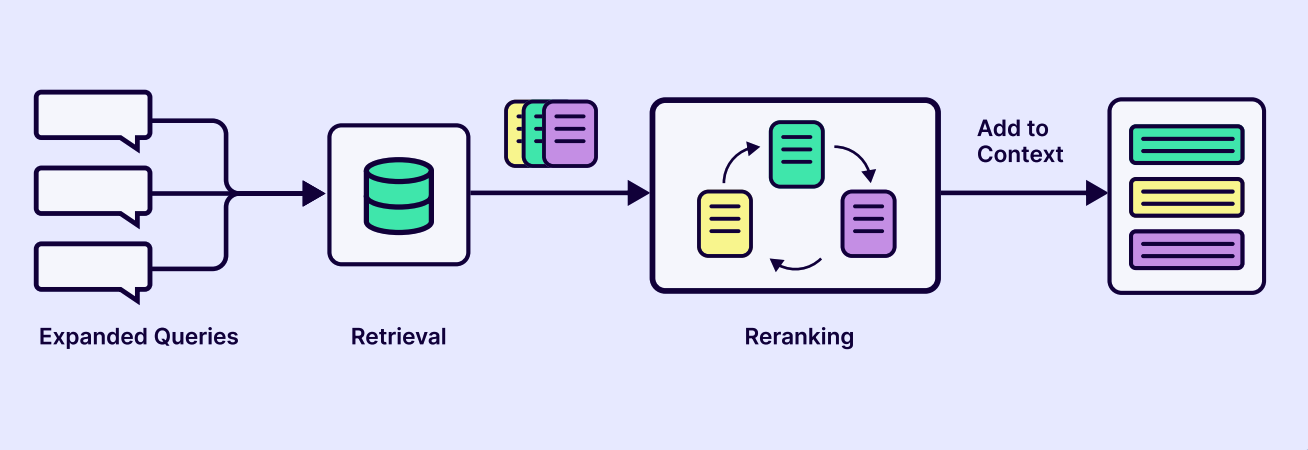
小结:记忆,是智能体的起点
最后,记忆是让 LLM 从“回答机器”进化为“具备理解能力的智能系统”的关键。有效的记忆并不是被动存储,而是一个主动管理的过程。理想的智能体,应当懂得:
- 该记什么 ( 有价值的经验 )
- 该忘什么 ( 过时或错误的信息 )
- 如何用过去照亮未来 ( 基于历史做出更好决策 )
这才是记忆真正的力量,它不只是存储,更是智能体持续成长的土壤。关于记忆的更多内容,也可以回顾 如何让上下文“干净又高效” 小节。
工具
如果说记忆赋予智能体一种自我意识,那么工具则赋予它“超能力”。单纯依靠自身,LLM 是出色的对话者和文本处理者,但它们生活在一个信息茧房中。它们无法查询当前天气、预订航班或查看实时股票价格。按照设计,它们与充满数据与行动的现实世界是脱节的。
这就是工具的用武之地。在智能体语境中,“工具”泛指一切能让 LLM 与外部系统交互的接口:API、数据库查询函数、代码解释器、浏览器自动化脚本,甚至其他智能体。通过工具,模型不仅能“知道”,还能“做到”。整合工具能让智能体从一个知识丰富的顾问,升级为真正能够完成任务的执行者。
但这并非简单地把 API 文档塞进提示词就完事。真正的挑战在于上下文工程:如何让智能体理解有哪些工具可用、何时该调用哪个工具、如何解析工具返回的结果,并基于这些结果继续推理和行动。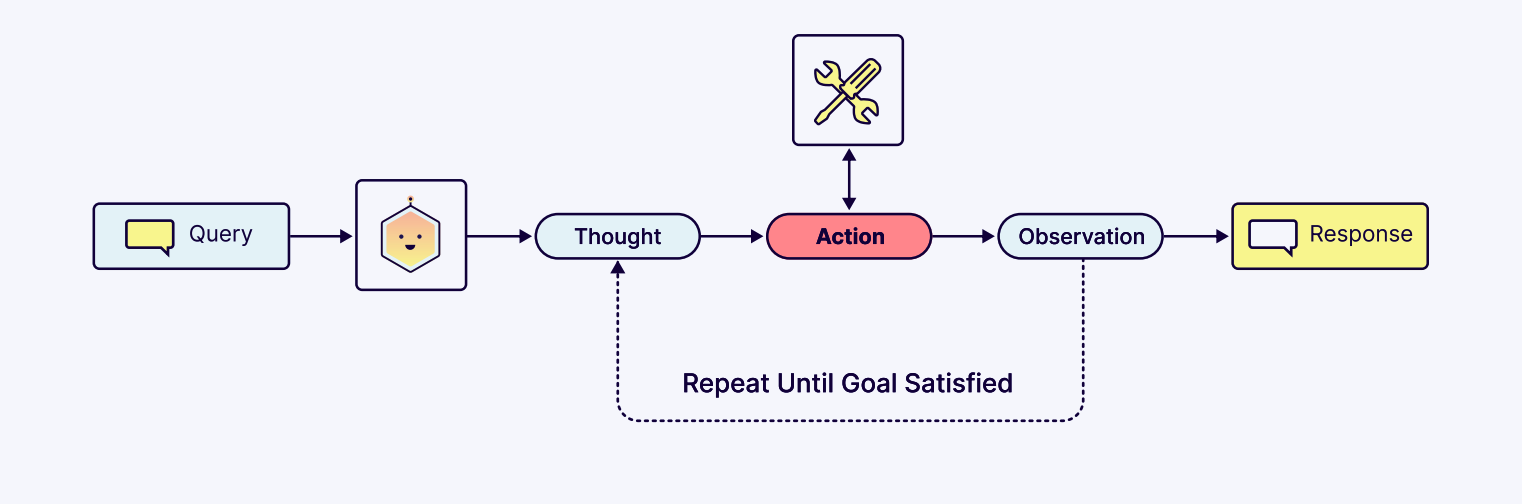
演化:从提示到行动
从最初到现在,工具使用的演化非常迅速。
起初,开发者尝试通过传统的“提示工程”让大模型执行某些动作,也就是“骗”模型生成看起来像命令的文本。比如:“请输出一行 Python 代码来获取天气”。但这种方式极其脆弱,模型可能生成格式错误的代码、虚构不存在的 API,或干脆拒绝“越界”行为。
真正的突破来自于函数调用(Function Calling),也被称为工具调用(Tool Calling)。如今,主流大模型 ( 如 GPT-4、Qwen 3、DeepSeek ) 都支持结构化工具调用:模型不再生成自然语言描述,而是输出标准 JSON,明确指定要调用的工具名称及其参数。例如:
{
"tool": "search_flights",
"arguments": {
"origin": "SFO",
"destination": "HND",
"date": "2025-12-16"
}
}
这个输出可被运行时直接解析并执行,极大提升了可靠性与安全性。有了这个能力,就出现了许多可能性:
- 简单工具 ( A Simple Tool ):例如,一个旅行 Agent 机器人可以使用一个叫 search_flights 的工具。当用户说“帮我找一趟下周二去东京的航班”时,大模型不会去“猜”答案,而是生成一个对该函数的调用,由这个函数去查询真实的航空公司 API。
- 工具链 ( A Chain of Tools ):对于更复杂的请求,比如“帮我规划一个去旧金山的周末旅行”,智能体可能需要将多个工具串联使用:find_flights、search_hotels、get_local_events 等。它必须具备推理、规划并执行多步工作流的能力。
而这一切的前提,是工具描述的质量。一个优秀的工具定义,就像给模型写了一份“微型说明书”:
def search_flights(origin: str, destination: str, date: str) -> List[Flight]:
"""
查询指定日期从 origin 到 destination 的可用航班。
- origin 和 destination 必须是 IATA 三字机场代码(如 SFO, HND)
- date 格式为 YYYY-MM-DD
- 返回最多 10 条航班记录,包含航班号、起飞时间、价格等字段
"""
这样的描述不仅说明“能做什么”,还明确了输入约束和输出结构,大幅降低误用风险。
协调的挑战
给一个智能体添加工具很容易,真正的难点在于:如何让它可靠、安全、有效地使用这些工具。上下文工程的核心任务,就是“协调”:管理信息流和决策流程,让智能体在推理时知道什么时候用哪个工具。
具体来说,有三大挑战:
工具选择不准确
模型可能面对十几个可用工具,但只有一两个适用于当前任务。如果提示中工具描述模糊、命名混乱,或缺乏示例,模型很容易选错。比如:
- 用户说:“查一下明天北京天气”,模型却调用了 search_news;
- 面对 10 个相似工具 ( 如 get_stock_price、get_historical_prices、get_market_summary ) ,模型随机选一个;
- 工具名称或描述模糊 ( 如 query_data ),导致模型无法判断用途。
模型依赖提示中的工具描述做决策,若描述不清、缺乏上下文或示例,就容易“猜错”,可选的解决方案有很多,比如:
- 结构化工具描述 + 强约束命名
- 工具名应体现功能,避免泛化词汇 ( 不用 tool1,而用 get_current_weather )
- 描述采用“动词+对象+约束”格式:“获取指定城市和日期的实时天气。仅支持中国主要城市,日期必须为今天或明天。”
- 在系统提示中显式列出可用工具清单,不要让模型“凭记忆”回想有哪些工具。每次推理前,在 prompt 开头清晰列出,比如:
You can use the following tools:
get_current_weather(city: str, date: str) → WeatherInfo
search_flights(origin: str, dest: str, date: str) → List[Flight]
- 提供 few-shot 示例 ( 尤其对复杂任务 )
参数构造错误
即使选对了工具,模型也可能传错参数,比如:
- 日期格式错误:传 “Dec 18” 而非 “2025-11-18”
- 字段缺失:调用航班搜索时漏掉 origin
- 类型错误:把数字 “1200” 当字符串传给价格参数(而 API 要求整数)
- 越权输入:用户说“查所有用户数据”,模型调用 list_users() 未加权限过滤。
LLM 生成的是自然语言思维,但工具需要严格结构化输入,两者之间存在“语义到语法”的鸿沟。常见的解决方案有:
- 使用 JSON Schema 强制参数校验,OpenAI Function Calling 原生支持 schema 校验,可查看相关文档
- 工具执行时对参数进行常见的容错处理,比如:即使模型传了 “tomorrow”,也在执行前自动转为实际日期
- 对高风险工具 ( 如数据库删除、支付 ),要求额外确认或校验权限,防止误触发。
- 敏感操作在沙箱中执行
结果解释与任务推进
工具返回的数据往往是原始 JSON 或表格,模型需要从中提取关键信息,并决定下一步动作。如果上下文里堆满了中间结果,模型可能迷失方向。比如:
- 工具返回 10 条航班,模型却只提了第一条
- 返回错误信息 ( 如“无符合条件航班” ),模型仍继续推进任务
- 上下文被大量原始 JSON 填满,模型“迷失”在细节中,忘了原始目标
工具输出是“原材料”,而模型需要的是“可行动的洞察”,未经处理的原始数据会稀释上下文信号。常见的解决方案有:
- 不直接把原始 API 响应塞进上下文,而是由执行层生成简洁摘要
- 在工作记忆中持续更新任务进度,模型每次决策都基于这个结构化状态,而非杂乱的历史对话
- 限制原始数据长度,优先保留元信息。如果必须传原始数据(如表格),只截取前 3 行 + 字段说明,并标注“共 N 条结果”
LangChain 的 ToolExecutor 支持自定义 parse_output 函数。如果使用 LangChain 可以在这个函数中实现总结摘要或自定义工具输出内容格式等操作。
接下来,我们用一个案例来说明这些关键步骤:Glowe,一个由 Elysia 协调框架驱动的护肤领域智能应用。
工具发现:Agent 首先需要知道自己有哪些工具可用。通常,这一步通过在系统提示中提供“工具列表及其描述”实现。描述的质量非常关键,因为它是智能体理解工具功能的唯一途径。只有通过清晰的描述,它才能判断什么时候该使用某个工具,什么时候不该使用。
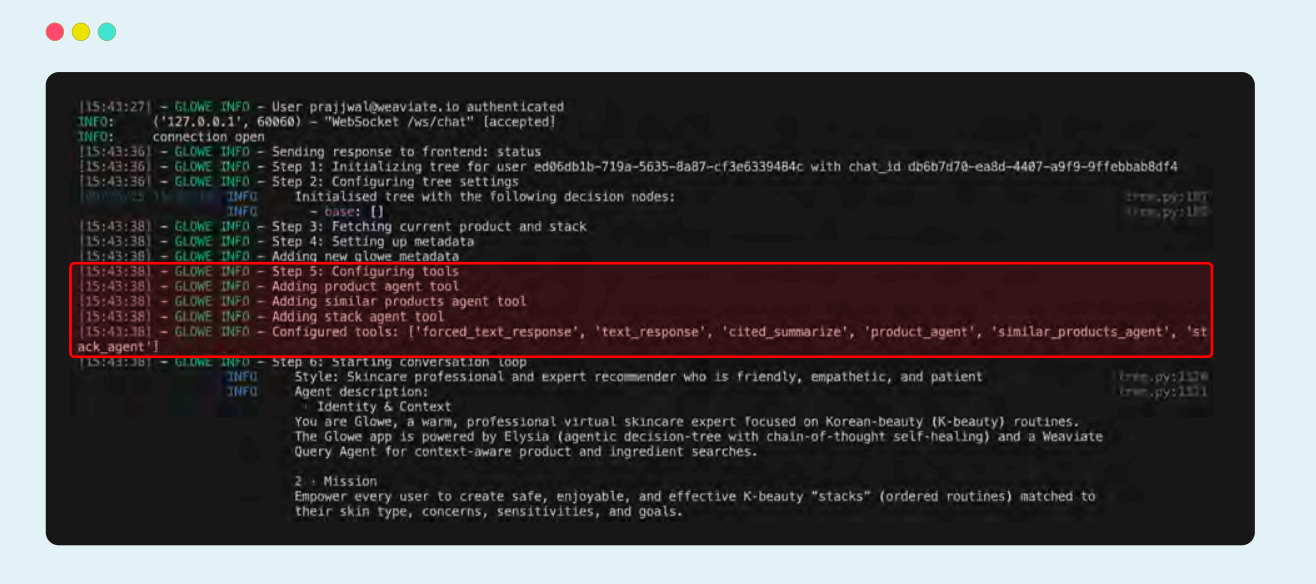
在 Glowe 中,我们在每一个新的聊天树初始化时(Step 5),都会配置一组专门的工具,并提供精确的描述。
工具选择与规划:当面对用户请求时,Agent 要判断是否需要使用工具。如果需要,它要决定使用哪个。对于复杂任务,它甚至需要串联多个工具来制定计划,比如:“先用天气工具搜索天气,然后用邮件工具发送摘要。”
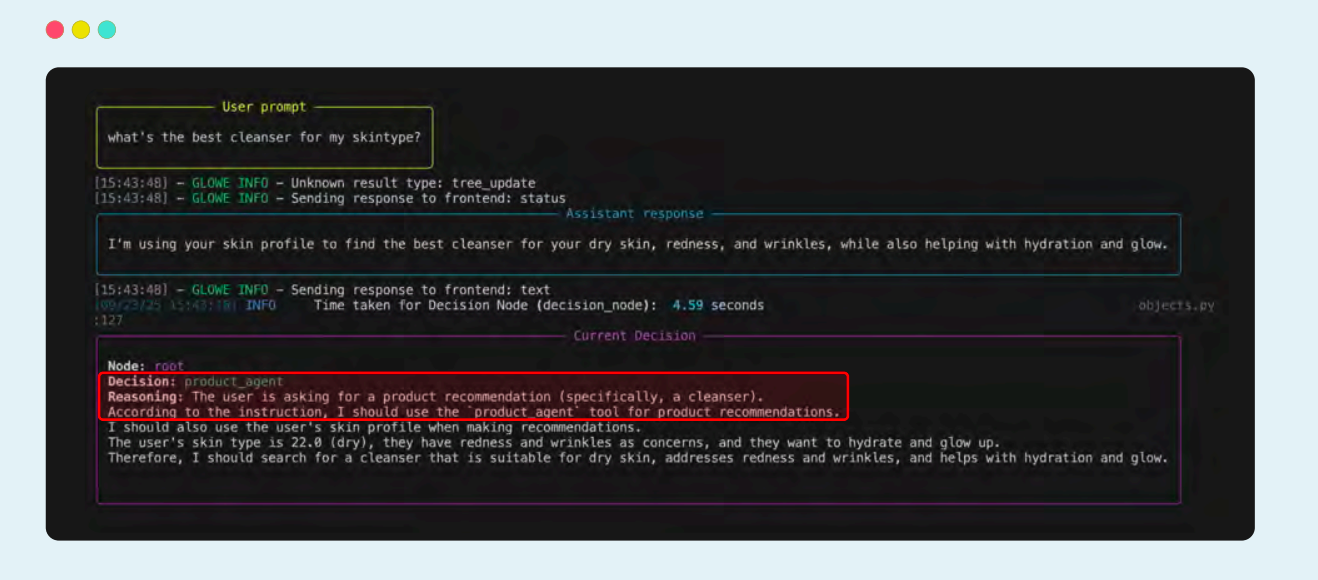
在这里,决策智能体正确地分析了用户的请求,并选择了 product_agent 工具。
参数构建:一旦选定了工具,Agent 要生成合适的参数。例如,如果工具是 get_weather(city, date),它需要从用户请求中提取“旧金山”和“明天”,并格式化为正确的输入。这一步也可能涉及生成结构化的请求或 API 调用。
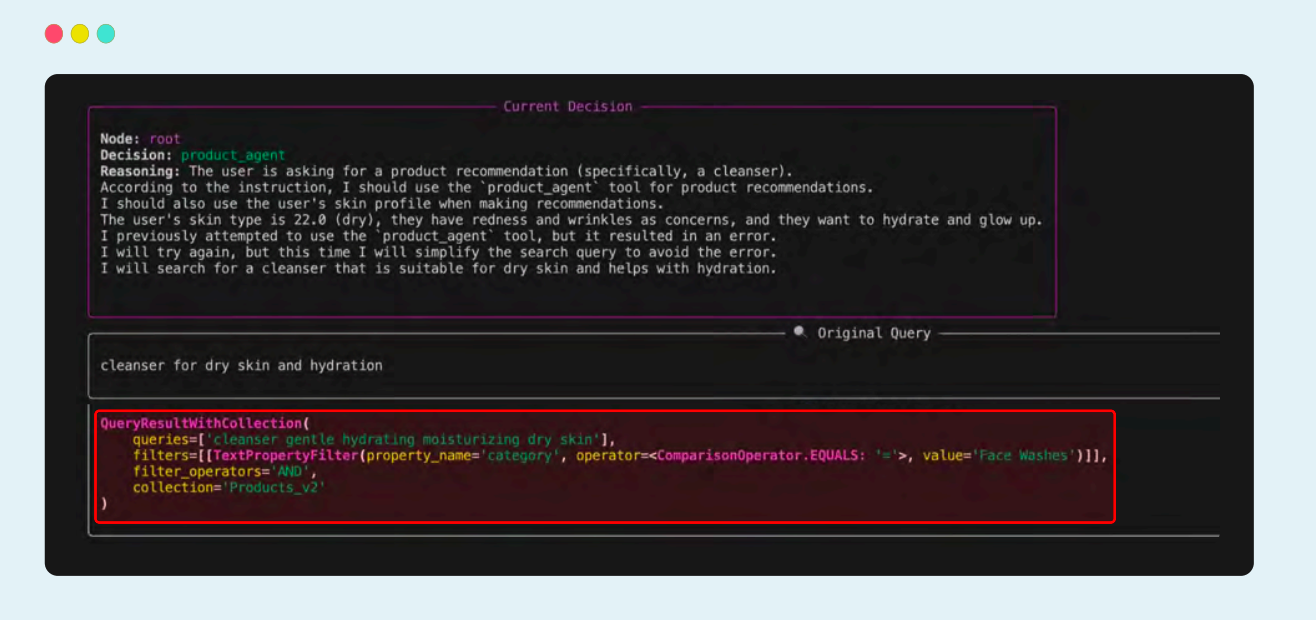
在这个案例中,product_agent 需要一个文本查询参数来搜索产品集合。注意,智能体在第一次生成了错误参数后,还能自动纠正(自愈能力),这是协调机制的另一关键部分。
反思:当工具执行完毕后,其输出(即“观察结果”)会被送回上下文窗口。智能体会根据这个输出进行反思,判断下一步该怎么做。比如:工具是否成功?是否产生了回答问题所需的信息?还是出现了错误,需要换一种方法?
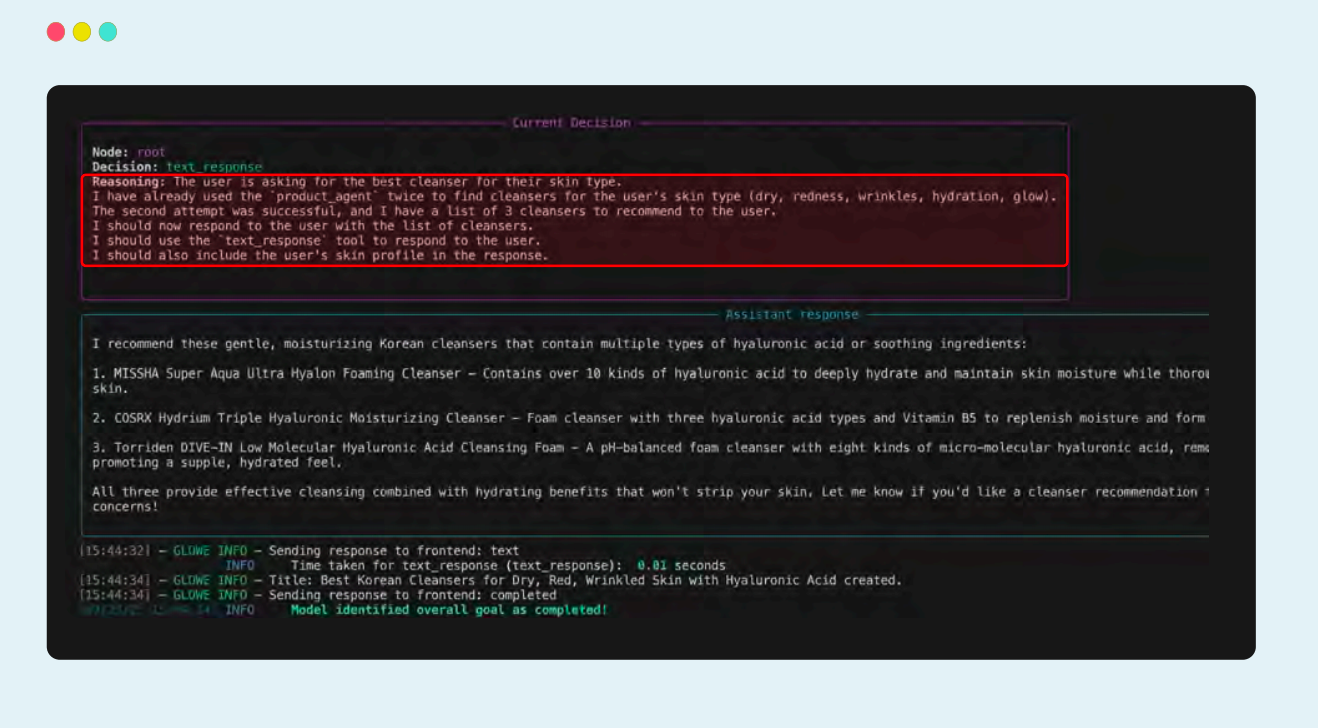
这一过程展示了协调机制中核心的反馈循环,也就是所谓的 “思考-行动-观察(Thought-Action-Observation)”循环。智能体会观察行动结果,用新信息推动下一步思考,决定任务是否完成、是否需要使用另一个工具,或者是否应向用户询问更多信息。这个循环就是现代智能体框架中的基础推理机制
工具使用的下一个前沿
工具使用正在走向标准化。虽然函数/工具调用的方式很好用,但它带来了一个碎片化的生态:每个 AI 应用都需要为每个外部系统做一次自定义集成。为了解决这个问题,Anthropic 在 2024 年末推出了 Model Context Protocol(MCP)。他们称其为“AI 的 USB-C”,一种通用标准,允许任何兼容 MCP 的 AI 应用连接到任何 MCP 服务器。
这样一来,开发者不再需要为每个工具写独立的集成,只需创建一个 MCP 服务器,将系统功能通过标准化接口暴露出来。任何支持 MCP 的 AI 应用都能通过基于 JSON-RPC 的协议轻松连接。这将原本的 MxN 集成问题 ( M 个应用需要分别对接 N 个工具 ) 转变为一个更简单的 M + N 问题。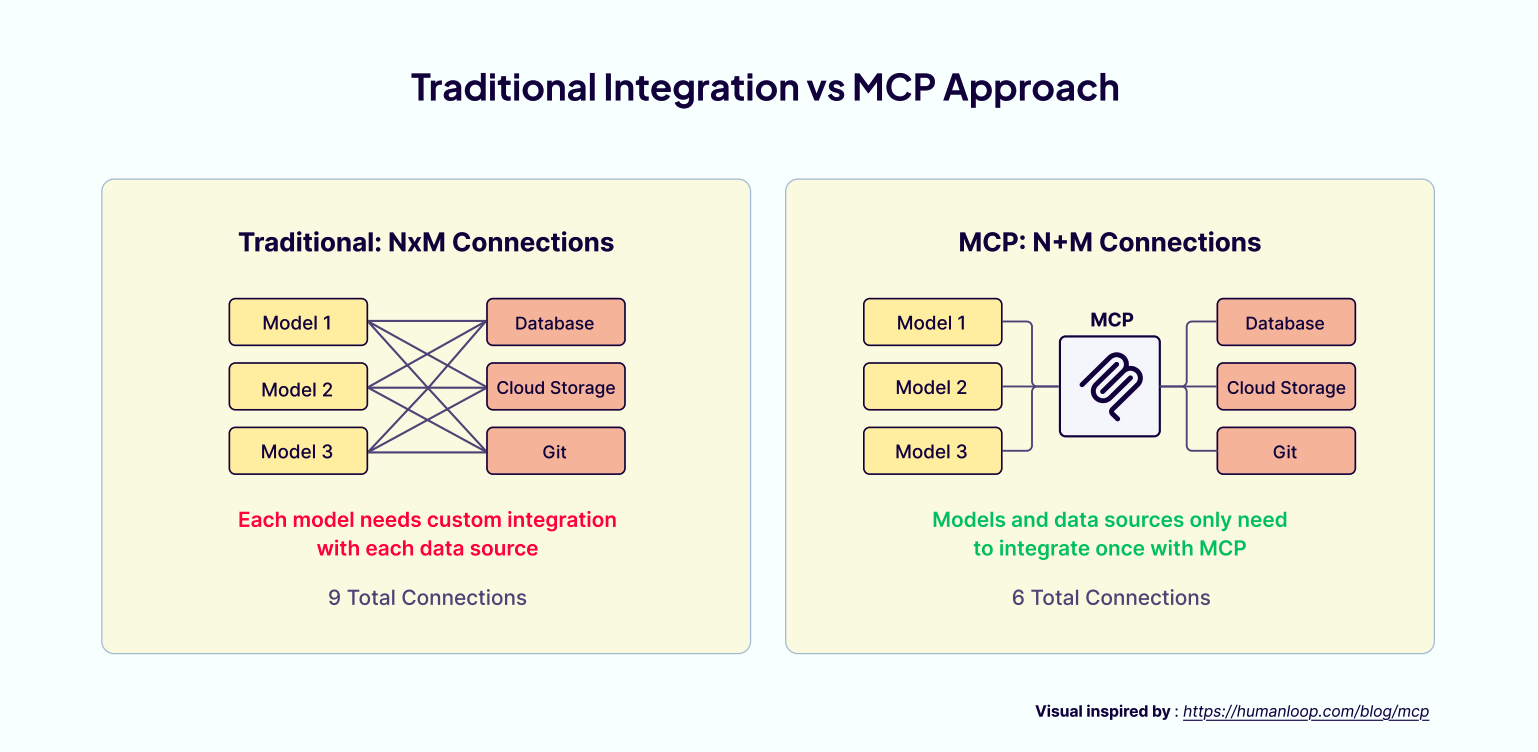
这一变化推动了可组合、模块化、标准化的 AI 工具架构,也让工程师的角色从“编写自定义集成”转变为“编排自适应系统”,让它们能无缝连接到任何外部系统。
最后
上下文工程远不止是为大模型编写提示词、构建检索系统,或设计 AI 架构。它更像是一种构建互联、动态系统的艺术,这些系统能够在各种使用场景和面对不同用户时,都稳定可靠地运行。本文中所描述的这些组件,无论是智能体、检索、记忆还是工具,都会随着新技术、新模型和新发现不断演进。然而,真正决定一个 AI 系统能否成功的关键,并不在于它的模型有多强大,而在于它是否能在整个架构中良好地设计并运用上下文。我们不再只是想着如何“提示一个模型”,而是在思考:如何为模型设计出一个完整的上下文系统架构。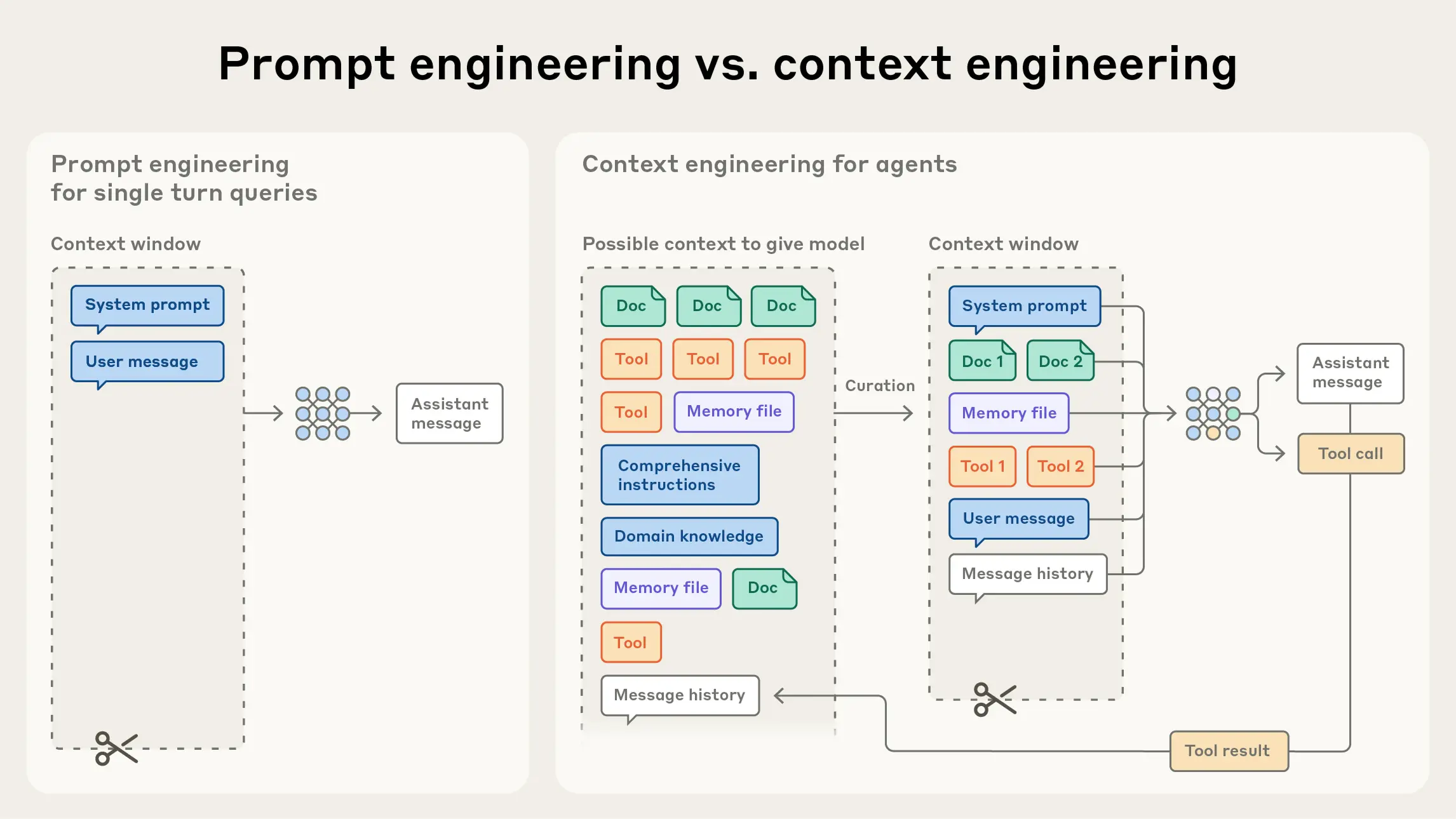
上下文工程由以下几个核心组件构成:
- 智能体:作为系统的决策“大脑”,负责思考与行动。
- 查询增强:把混乱的人类请求转化为可执行的意图。
- 检索:让模型能够连接到真实的事实与知识库。
- 记忆:赋予系统“历史感”和“学习能力”。
- 工具:让你的应用可以“动手”,与实时数据和外部 API 交互。
我们正在从“与模型对话的提示工程师”,转变为“为模型构建世界的系统架构师”。真正懂得这一点的开发者、工程师和创造者们都清楚一个事实:最优秀的 AI 系统并非来自更大的模型,而是来自更好的工程设计。
我们迫不及待地想看到,你会创造出怎样的未来。